The pythonchallenge game
If you want to practice your python,the pythonchallenge coulde help you.There are currently 33 levels.
python -v 2.7.13
The 0 level

http://www.pythonchallenge.com/pc/def/0.html
You must be count the num to change the URL
Answer

The 1 level

g fmnc wms bgblr rpylqjyrc gr zw fylb. rfyrq ufyr amknsrcpq ypc dmp. bmgle gr gl zw fylb gq glcddgagclr ylb rfyr'q ufw rfgq rcvr gq qm jmle. sqgle qrpgle.kyicrpylq() gq pcamkkclbcb. lmu ynnjw ml rfc spj.
The prompt is
K–>M o–>Q E–>G
According to the picture we know,we coulde encoded this text first.
Answer

I h o p e y o u d i d n t t r a n s l a t e i t b y h a n d .
t h a t s w h a t c o m p u t e r s a r e f o r .
d o i n g i t i n b y h a n d i s i n e f f i c i e n t a n d t h a t ' s w h y t h i s t e x t i s s o l o n g .
u s i n g s t r i n g .
m a k e t r a n s ( ) i s r e c o m m e n d e d .
n o w a p p l y o n t h e u r l .
LOL,if you translate it by hand,so inefficiency!
Now,it is so easy.Only change map to ocr
http://www.pythonchallenge.com/pc/def/map.html
RegExr can use \w/g get letters and tell you where they are.
source code
The 2 level

recognize the characters. maybe they are in the book,
but MAYBE they are in the page source.
We can open the web source

Answer


We can know the password is equality
http://www.pythonchallenge.com/pc/def/ocr.html
source code
str="g fmnc wms bgblr rpylqjyrc gr zw fylb. rfyrq ufyr amknsrcpq ypc dmp. bmgle gr gl zw fylb gq glcddgagclr ylb rfyr'q ufw rfgq rcvr gq qm jmle. sqgle qrpgle.kyicrpylq() gq pcamkkclbcb. lmu ynnjw ml rfc spj."
key=[chr(i) for i in range(97,123)]#字典键值为a-z
value=[chr(i) for i in range(99,123)]
for i in range(97,99):
value.append(chr(i))
#打包到一个字典里
z=dict(zip(key,value))
#添加字典
z[' ']=' '
z['(']='('
z[')']=')'
z['.']='.'
z['\'']='\''
t=False
u=list(str)
k=len(u)+1
for i in range(k):
print z[u[i]],
if z[u[i]]=='.':
print '\n'
if i==k:
t=True#循环到最后一个字符退出循环
The 3 level

One small letter, surrounded by EXACTLY three big bodyguards on each of its sides.
This level tell us how to use re which like xXXXxXXXx.
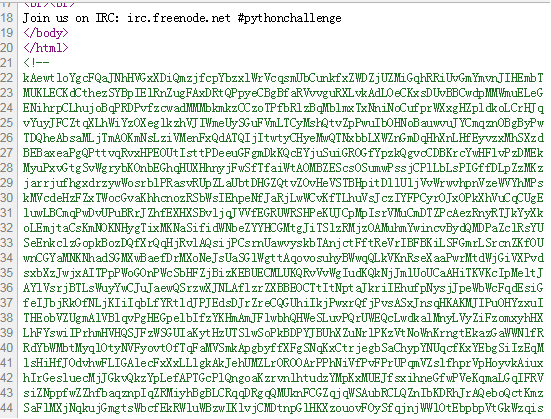
Answer


http://www.pythonchallenge.com/pc/def/equality.html
But the web change from html to php
source code
The 4 level

Check in the picture you will see the url http://www.pythonchallenge.com/pc/def/linkedlist.php?nothing=12345 and the body is and the next nothing is 44827
I found this is a hundreds loop,so I check in the web source.The prompt is
<!-- urllib may help. DON'T TRY ALL NOTHINGS, since it will never
end. 400 times is more than enough. -->
Answer

If you don’t know what is re and urllib2 you can check here.

http://www.pythonchallenge.com/pc/def/linkedlist.php?nothing=(\d+)
source code
import urllib2,re
r=re.compile(r'.*?(\d+)$')
nextnothing='12345'
i=1
t=True
while t:
try:
f=urllib2.urlopen('http://www.pythonchallenge.com/pc/def/linkedlist.php?nothing=%s'% nextnothing)
result=f.read()
f.close()
print i,result
nextnothing=r.search(result).group(1)
if nextnothing=='16044':
nextnothing='8022'
if result=='peak.html':
t=False
i+=1
except:
if result=='peak.html':
t=False
print 'error'
The 5 level

pronounce it
The best way is to see the source code
<html>
<head>
<title>peak hell</title>
<link rel="stylesheet" type="text/css" href="../style.css">
</head>
<body>
<center>
<img src="peakhell.jpg"/>
<br><font color="#c0c0ff">
pronounce it
<br>
<peakhell src="banner.p"/>
</body>
</html>
<!-- peak hell sounds familiar ? -->
You can notice that banner.p
It tell us that Persistent serialized storage of the python about pickle-Create portable serialized representations of Python objects.
The Tools is use like game save in the hard disk can serialize any type of data such as dict list into a string format.
Also has a module cPickle which for a (much) faster implementation becaus it is written by C,but it named pickle in Python3.
pickle functions
FUNCTIONS dump(obj, file, protocol=None)
dumps(obj, protocol=None)
load(file)
loads(str)
Answer


channel
http://www.pythonchallenge.com/pc/def/peak.html
source code
import urllib2,pprint
import cPickle as pickle
b=urllib2.urlopen('http://www.pythonchallenge.com/pc/def/banner.p')#get该地址文件,b类型为实例(isinstant)
result=pickle.Unpickler(b).load()#创造一个unpickler文件反序列化成list
pprint.pprint(result)#打印result
output=open('c:\\Users\\Administrator\\Desktop\\5text.txt','w')
for line in result:
print >> output, ' '.join([c[0]*c[1] for c in line])#元组(tuple)元素相乘转成字符串写入5text文件
output.close()#关闭文件
The 6 level

<!-- <-- zip -->
·····
change the http://www.pythonchallenge.com/pc/def/channel.html to http://www.pythonchallenge.com/pc/def/channel.zip, then download a zip file.
A readme.txt tell us
welcome to my zipped list.
hint1: start from 90052
hint2: answer is inside the zip
Every files in this zip has a string: “Next nothing is (a int number)”, so we need to travel these files match the number then find a final number
Answer
import re
c = 0
n = ['90052']#if chose other numbers, iteration will decrease
while n[0].isdigit():
c += 1
with open("/Users/jin/Downloads/channel/{}.txt".format(n[0]),"r+") as f:
r = f.readlines()
n = re.findall(r'(\d+)',r[0])
print(c, n[0])#c = 908
it returns 46145 finally which content is Collect the comments.
So we need to change our thought.
According to zipfile module, we know the zipfile has comment, so we should to collect the comments with zipfile module
**************************************************************
****************************************************************
****************************************************************
** **
** OO OO XX YYYY GG GG EEEEEE NN NN **
** OO OO XXXXXX YYYYYY GG GG EEEEEE NN NN **
** OO OO XXX XXX YYY YY GG GG EE NN NN **
** OOOOOOOO XX XX YY GGG EEEEE NNNN **
** OOOOOOOO XX XX YY GGG EEEEE NN **
** OO OO XXX XXX YYY YY GG GG EE NN **
** OO OO XXXXXX YYYYYY GG GG EEEEEE NN **
** OO OO XX YYYY GG GG EEEEEE NN **
** **
****************************************************************
**************************************************************
source code
import re
import zipfile
'''
c = 0
n = ['67824']
while n[0].isdigit():
c += 1
with open("/Users/jin/Downloads/channel/{}.txt".format(n[0]),"r+") as f:
r = f.readlines()
n = re.findall(r'(\d+)',r[0])
print(c, n[0])
**************************************************************
****************************************************************
****************************************************************
** **
** OO OO XX YYYY GG GG EEEEEE NN NN **
** OO OO XXXXXX YYYYYY GG GG EEEEEE NN NN **
** OO OO XXX XXX YYY YY GG GG EE NN NN **
** OOOOOOOO XX XX YY GGG EEEEE NNNN **
** OOOOOOOO XX XX YY GGG EEEEE NN **
** OO OO XXX XXX YYY YY GG GG EE NN **
** OO OO XXXXXX YYYYYY GG GG EEEEEE NN **
** OO OO XX YYYY GG GG EEEEEE NN **
** **
****************************************************************
**************************************************************
'''
s = '/Users/jin/Downloads/channel.zip'
z = zipfile.ZipFile(s,"r")
n = '90052.txt'
convert = '90052'
comments = []
while convert.isdigit():
#read the information in the archive
info = z.read(n)
#get comment from the txt
comment0 = z.getinfo(n).comment
#push to comments
comments.append(comment0)
#It need to translate byte to str to match numbers
info=str(info).encode("utf-8")
res = re.findall('\d', info)
convert = ''.join(res)
n = convert + '.txt'
end = ''
for c in comments:
end += str(c).encode("utf-8")
print(end)
The 7 level
it's in the air. look at the letters.
According to NASA, the gases in Earth’s atmosphere include: Nitrogen — 78 percent. Oxygen — 21 percent. Argon — 0.93 percent.
And oxygen is the second largest component of the atmosphere, comprising 20.8% by volume.
Answer
oxygen
The 8 level

We found no prompt in the source code.
Look at the picture carefully, it has a gray and white color block belt on the picture.
It may be tell us you need to use PIL to check these blocks
We found this picture’s size is 629x95 , mode is ‘RGBA’, and if you have learn the color’s knowledege, the gray and white block’s RGB has same values,like this (110,110,110)
Now , we collect these numbers
[115, 109, 97, 0, 14, 102, 159, 196, 219, 232, 197, 242, 255, 253, 247, 241, 114, 116, 32, 103, 117, 121, 44, 111, 100, 101, 105, 46, 104, 110, 120, 108, 118, 91, 49, 48, 53, 54, 51, 52, 50, 93]
We have learn decode/encode in 2nd level, so it is easy for us to change them to alphabet with chr
Help on built-in function chr in module builtin:
chr(…) chr(i) -> character
Return a string of one character with ordinal i; 0 <= i < 256.
We got this string
smart guy, you made it. the next level is [105, 110, 116, 101, 103, 114, 105, 116, 121]
Then translate again, got integrity
Answer
import requests
from PIL import Image
url = 'http://www.pythonchallenge.com/pc/def/oxygen.png'
r = requests.get(url)
f1 = '/Users/jin/Desktop/oxygen.png'
with open(f1,'wb') as f:
f.write(r.content)
f.close()
im = Image.open(f1)
s = ''
for i in range(0, im.size[0], 7):
if im.getpixel((i,47))[0] == im.getpixel((i,47))[1] and im.getpixel((i,47))[0] == im.getpixel((i,47))[2]:
s += ''.join(chr(im.getpixel((i,47))[0]))
print s
s=''
a = [...]#the numbers in the string
for i in range(len(a)):
s+=''.join(chr(a[i]))
Source code
The 8 level

Show the source
<html>
<head>
<title>working hard?</title>
<link rel="stylesheet" type="text/css" href="../style.css">
</head>
<body>
<br><br>
<center>
<img src="integrity.jpg" width="640" height="480" border="0" usemap="#notinsect"/>
<map name="notinsect">
<area shape="poly"
coords="179,284,214,311,255,320,281,226,319,224,363,309,339,222,371,225,411,229,404,242,415,252,428,233,428,214,394,207,383,205,390,195,423,192,439,193,442,209,440,215,450,221,457,226,469,202,475,187,494,188,494,169,498,147,491,121,477,136,481,96,471,94,458,98,444,91,420,87,405,92,391,88,376,82,350,79,330,82,314,85,305,90,299,96,290,103,276,110,262,114,225,123,212,125,185,133,138,144,118,160,97,168,87,176,110,180,145,176,153,176,150,182,137,190,126,194,121,198,126,203,151,205,160,195,168,217,169,234,170,260,174,282"
href="../return/good.html" />
</map>
<br><br>
<font color="#303030" size="+2">Where is the missing link?</font>
</body>
</html>
<!--
un: 'BZh91AY&SYA\xaf\x82\r\x00\x00\x01\x01\x80\x02\xc0\x02\x00 \x00!\x9ah3M\x07<]\xc9\x14\xe1BA\x06\xbe\x084'
pw: 'BZh91AY&SY\x94$|\x0e\x00\x00\x00\x81\x00\x03$ \x00!\x9ah3M\x13<]\xc9\x14\xe1BBP\x91\xf08'
-->
Firstly, I click this link http://www.pythonchallenge.com/pc/return/good.html , it tell us to input a username and password to login
Then I see the source code again, I found it has two prompts map coords and un,pw
The un and pw must be unsername and password
It has same characters in the begin “BZh91AY”, I found it is bz2 de/encode algorithm after google it.
Help on built-in function decompress in module bz2:
decompress(…) decompress(data) -> decompressed data
Decompress data in one shot. If you want to decompress data sequentially, use an instance of BZ2Decompressor instead.
Answer
import re
import bz2
import requests
url = "http://www.pythonchallenge.com/pc/def/integrity.html"
r = requests.get(url)
un = re.findall(r'un: \'(.*?)\'', r.content)[0]
pw = re.findall(r'pw: \'(.*?)\'', r.content)[0]
print("Username: {}\nPassword: {}\n".format(bz2.decompress(un), bz2.decompress(pw)))
The 9 level

<!--
first+second=?
first:
146,399,163,403,170,393,169,391,166,386,170,381,170,371,170,355,169,346,167,335,170,329,170,320,170,
310,171,301,173,290,178,289,182,287,188,286,190,286,192,291,194,296,195,305,194,307,191,312,190,316,
190,321,192,331,193,338,196,341,197,346,199,352,198,360,197,366,197,373,196,380,197,383,196,387,192,
389,191,392,190,396,189,400,194,401,201,402,208,403,213,402,216,401,219,397,219,393,216,390,215,385,
215,379,213,373,213,365,212,360,210,353,210,347,212,338,213,329,214,319,215,311,215,306,216,296,218,
290,221,283,225,282,233,284,238,287,243,290,250,291,255,294,261,293,265,291,271,291,273,289,278,287,
279,285,281,280,284,278,284,276,287,277,289,283,291,286,294,291,296,295,299,300,301,304,304,320,305,
327,306,332,307,341,306,349,303,354,301,364,301,371,297,375,292,384,291,386,302,393,324,391,333,387,
328,375,329,367,329,353,330,341,331,328,336,319,338,310,341,304,341,285,341,278,343,269,344,262,346,
259,346,251,349,259,349,264,349,273,349,280,349,288,349,295,349,298,354,293,356,286,354,279,352,268,
352,257,351,249,350,234,351,211,352,197,354,185,353,171,351,154,348,147,342,137,339,132,330,122,327,
120,314,116,304,117,293,118,284,118,281,122,275,128,265,129,257,131,244,133,239,134,228,136,221,137,
214,138,209,135,201,132,192,130,184,131,175,129,170,131,159,134,157,134,160,130,170,125,176,114,176,
102,173,103,172,108,171,111,163,115,156,116,149,117,142,116,136,115,129,115,124,115,120,115,115,117,
113,120,109,122,102,122,100,121,95,121,89,115,87,110,82,109,84,118,89,123,93,129,100,130,108,132,110,
133,110,136,107,138,105,140,95,138,86,141,79,149,77,155,81,162,90,165,97,167,99,171,109,171,107,161,
111,156,113,170,115,185,118,208,117,223,121,239,128,251,133,259,136,266,139,276,143,290,148,310,151,
332,155,348,156,353,153,366,149,379,147,394,146,399
second:
156,141,165,135,169,131,176,130,187,134,191,140,191,146,186,150,179,155,175,157,168,157,163,157,159,
157,158,164,159,175,159,181,157,191,154,197,153,205,153,210,152,212,147,215,146,218,143,220,132,220,
125,217,119,209,116,196,115,185,114,172,114,167,112,161,109,165,107,170,99,171,97,167,89,164,81,162,
77,155,81,148,87,140,96,138,105,141,110,136,111,126,113,129,118,117,128,114,137,115,146,114,155,115,
158,121,157,128,156,134,157,136,156,136
-->
After connect these node, I got 2 pictures

It is a bull/cow, so try every words
ps: If you try cow, it will tell you hmm. it's a male.
Answer
from PIL import Image
a = [146,399,163,403,170,393,169,391,166,386,170,381,170,371,170,355,169,346,167,335,170,329,170,320,170,
310,171,301,173,290,178,289,182,287,188,286,190,286,192,291,194,296,195,305,194,307,191,312,190,316,
190,321,192,331,193,338,196,341,197,346,199,352,198,360,197,366,197,373,196,380,197,383,196,387,192,
389,191,392,190,396,189,400,194,401,201,402,208,403,213,402,216,401,219,397,219,393,216,390,215,385,
215,379,213,373,213,365,212,360,210,353,210,347,212,338,213,329,214,319,215,311,215,306,216,296,218,
290,221,283,225,282,233,284,238,287,243,290,250,291,255,294,261,293,265,291,271,291,273,289,278,287,
279,285,281,280,284,278,284,276,287,277,289,283,291,286,294,291,296,295,299,300,301,304,304,320,305,
327,306,332,307,341,306,349,303,354,301,364,301,371,297,375,292,384,291,386,302,393,324,391,333,387,
328,375,329,367,329,353,330,341,331,328,336,319,338,310,341,304,341,285,341,278,343,269,344,262,346,
259,346,251,349,259,349,264,349,273,349,280,349,288,349,295,349,298,354,293,356,286,354,279,352,268,
352,257,351,249,350,234,351,211,352,197,354,185,353,171,351,154,348,147,342,137,339,132,330,122,327,
120,314,116,304,117,293,118,284,118,281,122,275,128,265,129,257,131,244,133,239,134,228,136,221,137,
214,138,209,135,201,132,192,130,184,131,175,129,170,131,159,134,157,134,160,130,170,125,176,114,176,
102,173,103,172,108,171,111,163,115,156,116,149,117,142,116,136,115,129,115,124,115,120,115,115,117,
113,120,109,122,102,122,100,121,95,121,89,115,87,110,82,109,84,118,89,123,93,129,100,130,108,132,110,
133,110,136,107,138,105,140,95,138,86,141,79,149,77,155,81,162,90,165,97,167,99,171,109,171,107,161,
111,156,113,170,115,185,118,208,117,223,121,239,128,251,133,259,136,266,139,276,143,290,148,310,151,
332,155,348,156,353,153,366,149,379,147,394,146,399]
b = [156,141,165,135,169,131,176,130,187,134,191,140,191,146,186,150,179,155,175,157,168,157,163,157,159,
157,158,164,159,175,159,181,157,191,154,197,153,205,153,210,152,212,147,215,146,218,143,220,132,220,
125,217,119,209,116,196,115,185,114,172,114,167,112,161,109,165,107,170,99,171,97,167,89,164,81,162,
77,155,81,148,87,140,96,138,105,141,110,136,111,126,113,129,118,117,128,114,137,115,146,114,155,115,
158,121,157,128,156,134,157,136,156,136]
first = a+b
first = zip(first[::2], first[1::2])
yellow = (255, 238, 25)
im = Image.new("RGB", (640,480))
for i in range(len(first)):
im.putpixel(first[i], yellow)
im.save("/Users/jin/Desktop/first.png")
Source code
The 10 level
len(a[30]) = ?
Click the bull, you will go to this link http://www.pythonchallenge.com/pc/return/sequence.txt
a = [1, 11, 21, 1211, 111221,
This is a law problem, next number is to count the previous number which has same characters like ‘11’ is mean one ‘1’ 21 -> Two ‘1’ = 1 1211 -> One ‘2’ + One ‘1’ = 21 111221 -> One ‘1’ + One ‘2’ + Two ‘1’ = 1211
After you change bull to the number, it will direct to login webpage, input the un: huge pw: file
Answer
a = '111221'
k = 4
while k < 30:
j = 0
s = ''
while j < len(a):
c = 1
while j < len(a)-1 and a[j] == a[j+1]:
c += 1
j += 1
s = "{}{}{}".format(s, c, a[j])
j += 1
k += 1
a = s
print len(a)
Source code
The 11 level

The source code has no obvious prompt, but the title is odd even, it tell us we need to collect the odd pixels and even pixels to make up a picture

Answer
from PIL import Image
#import requests
f1 = "/Users/jin/Desktop/cave.jpg"
#r = requests.get('http://www.pythonchallenge.com/pc/return/cave.jpg')
#with open(f1,'wb') as f:
# f.write(r.content)
im = Image.open(f1)
odd = Image.new(im.mode, (im.size[0]/2, im.size[1]/2))
even = Image.new(im.mode, (im.size[0]/2, im.size[1]/2))
for x in range(1,im.size[0],2):
for y in range(1,im.size[1],2):
odd.putpixel(((x-1)/2,(y-1)/2),im.getpixel((x,y)))
for x in range(1,im.size[0],2):
for y in range(1,im.size[1],2):
even.putpixel((x/2,y/2),im.getpixel((x,y)))
odd.save('/Users/jin/Desktop/odd.jpg')
even.save('/Users/jin/Desktop/even.jpg')
Source code
The 12 level
 It only has a piture which name is evil1
It only has a piture which name is evil1
Change the http://www.pythonchallenge.com/pc/return/evil1.jpg to http://www.pythonchallenge.com/pc/return/evil2.jpg
{kind=link}

change the name it will download a picture, the every interval 5 bytes in the file is distributed to five jpg
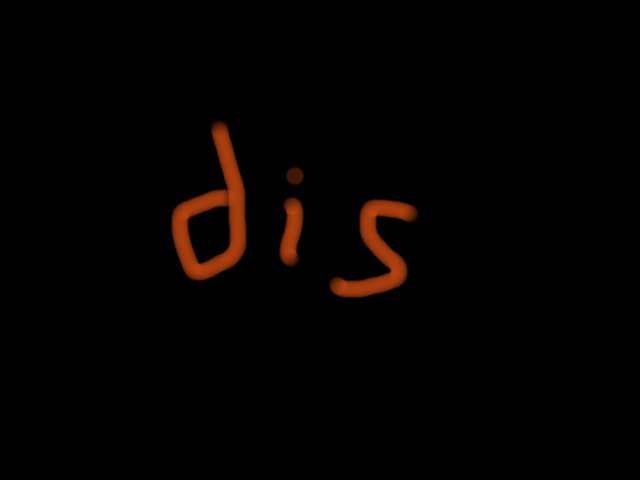




Try to concatenate them but remove the ity
Answer
from PIL import Image
p = '/Users/jin/Desktop/'
f = open('/Users/jin/Downloads/evil2.gfx', 'rb')
f_info = f.read()
f.close()
for i in range(5):
with open(p+str(i)+'.jpg', 'wb') as fp:
fp.write(f_info[i::5])
Source code
The 13 level

Click the 5 , it wil direct to http://www.pythonchallenge.com/pc/phonebook.php
The XML and phone tell us it need to use XML to handle and send HTTP to someone
xmlrpclib is built in module in python
Help on module xmlrpclib:
NAME xmlrpclib - An XML-RPC client interface for Python.
FILE /Library/Frameworks/Python.framework/Versions/2.7/lib/python2.7/xmlrpclib.py
MODULE DOCS https://docs.python.org/library/xmlrpclib
DESCRIPTION The marshalling and response parser code can also be used to implement XML-RPC servers.
But you need to know who should call. In previous level, we found evil4.jpg is a square, but it may be has information.
Answer
#coding: utf-8
#Author: Toryun
#Date: 2020-06-17 01:13:00
import urllib2
import xmlrpclib
from contextlib import closing
url0 = 'http://www.pythonchallenge.com'
url1 = 'http://www.pythonchallenge.com/pc/return/evil4.jpg'
url2 = 'http://www.pythonchallenge.com/pc/phonebook.php'
#create a default password manager
PasswordMgr1 = urllib2.HTTPPasswordMgrWithDefaultRealm()
#add password , uri and realm to instance,(“realm”, it refers to the protection scope of current certification。)
#like /protected_docs is realm
#GET /protected_docs HTTP/1.1
#Host: 127.0.0.1:3000
PasswordMgr1.add_password(None, url0, 'huge', 'file')
#create a instance of basice authhanlder which has password and username
auth_handler = urllib2.HTTPBasicAuthHandler(PasswordMgr1)
#Create an opener object from a list of handlers.
#The opener will use several default handlers, including support
#for HTTP, FTP and when applicable, HTTPS.
#If any of the handlers passed as arguments are subclasses of the
#default handlers, the default handlers will not be used.
op = urllib2.build_opener(auth_handler)
urllib2.install_opener(op)
#closing the with ... as automaticlly
with closing(urllib2.urlopen(url1)) as f:
#check who we should call
print(f.read().decode('utf-8'))
#use xmlrpclib.ServerProxy class to conntect the pythonchallenge.com
xmlrpc = xmlrpclib.ServerProxy(url2)
print(xmlrpc.phone('Bert'))
Source code
The 14 level


<!-- remember: 100*100 = (100+99+99+98) + (... -->
‘100+99+99+98’ it means move around the outermost in a counter anti-clockwise direction, down 100, right 99, up 99, left 98 We found that the picture in the buttom that the size is (10000, 1) the mode is ‘RGB’
allSteps = [[i, i-1, i-1, i-2] for i in range(100, 0, -2)]
We need to change the wire.png to square picture
We will get a cat picture

Answer
import urllib2
from contextlib import closing
from PIL import Image,ImageFile
ImageFile.LOAD_TRUNCATED_IMAGES = True
'''
url0 = 'http://www.pythonchallenge.com'
url1 = 'http://www.pythonchallenge.com/pc/return/wire.png'
PasswordMgr1 = urllib2.HTTPPasswordMgrWithDefaultRealm()
PasswordMgr1.add_password(None, url0, 'huge', 'file')
auth_handler = urllib2.HTTPBasicAuthHandler(PasswordMgr1)
op = urllib2.build_opener(auth_handler)
urllib2.install_opener(op)
with closing(urllib2.urlopen(url1)) as f:
b = open('/Users/jin/Desktop/wire.png','wb')
b.write(f.read())
'''
t = '/Users/jin/Desktop/wire.png'
t0 = '/Users/jin/Desktop/14.png'
im = Image.open(t)
data = list(im.getdata())
#create new image object
im0 = Image.new(im.mode, (100,100))
#Allocates storage for the image and loads the pixel data. In normal cases, you don’t need to call this method, since the Image class automatically loads an opened image when it is accessed for the first time. This method will close the file associated with the image.
data0 = im0.load()
allsteps = [[i, i-1, i-1, i-2] for i in range(100, 0, -2)]
#reduce the dimension
nsteps = reduce(lambda x, y: x+y, allsteps)
#right, up, left, down
directions = [(1,0), (0,1), (-1,0), (0,-1)]
direction = 0
pos = 0
#start_coord(0,0)
pos0 = (-1, 0)
for i in nsteps:
#forword i steps
for j in range(i):
#control the direction
pos0 = tuple(map(lambda x,y: x+y, pos0, directions[direction]))
#write the pixel fo wire.png to new picture
data0[pos0] = data[pos]
pos += 1
#change direction
direction = (direction + 1) % 4
im0.save(t0)
Source code
The 15 level

<html>
<head>
<title>whom?</title>
<link rel="stylesheet" type="text/css" href="../style.css">
</head>
<body>
<br><center>
<!-- he ain't the youngest, he is the second -->
<img src="screen15.jpg"><br>
</body>
</html>
<!-- todo: buy flowers for tomorrow -->
We found that the thumbnail in right bottom is Feb, and Feb has 29th, it means this year is leap year.
I think the solution is to find the leap year of the lead
he ain't the youngest, he is the second tell us his birthday’s rank, google it
Answer
from datetime import date
year = [i for i in xrange(1006, 1997) if ((i%4 == 0 or i%400 == 0) and i%100 != 0) and str(i)[-1] == '6']
birthday = []
for i in year:
if date(i, 1, 27).weekday() == 1:
birthday.append(i)
print(birthday)
Source code
The 16 level

<html>
<head>
<title>let me get this straight</title>
<link rel="stylesheet" type="text/css" href="../style.css">
</head>
<body>
<br><center>
<img src="mozart.gif"><br>
</body>
</html>
Let us solve what the image want to express.
from PIL import Image
im = Image.open('/Users/jin/Desktop/mozart.gif')
w, h = im.size#(640,480)
m = im.mode #'p'
#change to 'rgb' mode
im_rgb = im.convert()
pixels = [im_rgb.getpixel((c, r)) for r in range(h) for c in range(w)]
for i in pixels:
print(i)
You will find purple rgb value in here (255, 0, 255)
(153, 51, 51)
(247, 247, 247)
(255, 0, 255)
(255, 0, 255)
(255, 0, 255)
(255, 0, 255)
(255, 0, 255)
(251, 251, 251)
(102, 51, 51)
Count how many pixels of purple in the image
c = 0
for j in pixels:
if j == (255, 0, 255):
c += 1
print(c)#2400
2400/480 = 5 it means every rows have 5 purple pixels, and we need to put the purple straightly
Answer
from PIL import Image
im = Image.open('/Users/jin/Desktop/mozart.gif')
im_new = Image.new('RGB',(640, 480))#make a new image
w, h = im.size
im_rgb = im.convert("RGB")
p = []
purple = (255, 0, 255)
for i in range(h):
p.append([im_rgb.getpixel((c, i)) for c in range(w)])
for i in range(h):
pos = p[i].index(purple)
p[i] = p[i][pos:] + p[i][:pos]
for j in range(w):
im_new.putpixel((j,i), p[i][j])
im_new.show()

Source code
The 17 level

The tip in bottom-left corner is the 4th level