Timsort
| EN | CN |
The sort() in python is usually used in our program, now we study the Timesort algorithm which is made by Tim Peters in 2002.
Time complexity
 In the worst case, Timsort takes {\displaystyle O(n\log n)}O(n\log n) comparisons to sort an array of n elements. In the best case, which occurs when the input is already sorted, it runs in linear time, meaning that it is an adaptive sorting algorithm.
In the worst case, Timsort takes {\displaystyle O(n\log n)}O(n\log n) comparisons to sort an array of n elements. In the best case, which occurs when the input is already sorted, it runs in linear time, meaning that it is an adaptive sorting algorithm.
It is advantageous over Quicksort for sorting object references or pointers because these require expensive memory indirection to access data and perform comparisons and Quicksort’s cache coherence benefits are greatly reduced.
Get inspired from Merge Sort
- Can we make merges faster?
- Can we perform fewer merges?
- Are there cases where we’re actually better off doing something different and not using mergesort?
Timsort’s sorting steps
-
Timsort performs a binary search to find the location where the first element of the second run would be inserted in the first ordered run, keeping it ordered.
-
It performs the same algorithm to find the location where the last element of the first run would be inserted in the second ordered run, keeping it ordered
-
the smaller of the remaining elements of the two runs is copied into temporary memory, and elements are merged with the larger run into the now free space. If the first run is smaller, the merge starts at the beginning; if the second is smaller, the merge starts at the end. This optimization reduces the number of required element movements, the running time and the temporary space overhead in the general case.

Minrun is chosen from the range 32 to 64 inclusive, such that the size of the data, divided by minrun, is equal to, or slightly less than, a power of two. The final algorithm takes the six most significant bits of the size of the array, adds one if any of the remaining bits are set, and uses that result as the minrun. This algorithm works for all arrays, including those smaller than 64; for arrays of size 63 or less, this sets minrun equal to the array size and Timsort reduces to an insertion sort.
See the Tim Peter’s description
Computing minrun
If N < 64, minrun is N. IOW, binary insertion sort is used for the whole array then; it’s hard to beat that given the overheads of trying something fancier.
When N is a power of 2, testing on random data showed that minrun values of 16, 32, 64 and 128 worked about equally well. At 256 the data-movement cost in binary insertion sort clearly hurt, and at 8 the increase in the number of function calls clearly hurt. Picking some power of 2 is important here, so that the merges end up perfectly balanced (see next section). We pick 32 as a good value in the sweet range; picking a value at the low end allows the adaptive gimmicks more opportunity to exploit shorter natural runs.
static Py_ssize_t
merge_compute_minrun(Py_ssize_t n)
{
Py_ssize_t r = 0; /* becomes 1 if any 1 bits are shifted off */
assert(n >= 0);
while (n >= 64) {
r |= n & 1;
n >>= 1;
}
return n + r;
}
nRemaining = hi - lo
minrun = merge_compute_minrun(nRemaining)
Insertion Sort
if Next element bigger than forward number, swap them even the i bigger than list’s length

You could see my code heresource code
binary search
 You could see my code here source code
You could see my code here source code
Merge Sort
-
The array will be split to many small list
-
Sorting every smaill list
-
Merge list from left then right
You could see the my code here source code
Quick Sort
-
Select one temp number, compare two number with temp
-
If a[i] bigger than tmp, don’t move i,j–, when a[j] lower than tmp, swap a[i] and a [j]
-
If a[j] lower than tmp, don’t move j, i++, when a[i] bigger than tmp, swap a[i] and a[j]
-
When i > j, swap the a[j] and tmp
-
Return the 2 lists to function, sort again.(Repeat from 1 to 4 steps) Divide and Conquer
You could see my code here source code
Reference
Timsort - 中文维基百科
Timsort 是一种混合稳定的排序算法,源自归并排序和插入排序,旨在较好地处理真实世界中各种各样的数据。 它使用了 Peter Mcllroy 的”乐观排序和信息理论上复杂性”中的技术,参见 第四届年度ACM-SIAM离散算法研讨会论文集,第467-474页,1993年。 它由 Tim Peters 在2002年实现,并应用于 Python编程语言。该算法通过查找已经排好序的数据子序列,在此基础上对剩余部分更有效地排序。 该算法通过不断地将特定子序列(称为一个 run )与现有的 run 合并,直到满足某些条件为止来达成的更有效的排序。 从 2.3 版本起,Timsort 一直是 Python 的标准排序算法。 它还被 Java SE7, Android platform, GNU Octave, 谷歌浏览器,[7] 和 Swift[8] 用于对非原始类型的数组排序。
从归并排序中获得的思考
如果你看过归并排序的实现,你会发现其实所有的工作都是在合并(merge)的过程当中完成的。所以优化的重点也就落在了这里。由此我们得出以下三点可能的优化途径:
- 能否使合并过程运行的更快?
- 能否执行更少的合并过程?
- 是否存在一些与其使用归并排序不如使用其他排序的情况?
核心过程
-
查找部分有序数组长度并且最好是2的幂,如果长度小于某个值minrun,直接用二分插入排序算法进行合并,如果是降序,则直接反转数组
-
找到各个run,并入栈
-
按规则合并run(x>y+z and y>z) (规则:1. len[-3] > len[-2] + len[-1] && 2. len[-2] > len[-1])
Computing minrun
If N < 64, minrun is N. IOW, binary insertion sort is used for the whole array then; it’s hard to beat that given the overheads of trying something fancier.
When N is a power of 2, testing on random data showed that minrun values of 16, 32, 64 and 128 worked about equally well. At 256 the data-movement cost in binary insertion sort clearly hurt, and at 8 the increase in the number of function calls clearly hurt. Picking some power of 2 is important here, so that the merges end up perfectly balanced (see next section). We pick 32 as a good value in the sweet range; picking a value at the low end allows the adaptive gimmicks more opportunity to exploit shorter natural runs.
Tim Peter 认为如果元素个数在64的情况下,minrun就是整个数组长度。使用二分插入排序,会得到很好的效果。
如前所述, 我们知道当 run 的数目等于或略小于2的幂时,合并两个数组最为有效。所以 Timsort 选择范围为 [32,64] 的 minrun,使得原始数组的长度除以 minrun 时(n/minrun),等于或略小于2的幂。
具体而言,选择数组长度的六个最高标志位,如果其余的标志位被设置,则加1:
-
189:10111101,取前六个最高标志位为101111(47),同时最后两位为01,所以 minrun 为47+1,[n/minrun]=4 满足要求。
-
976:11 1101 0000,取前六个最高标志位为111101(61),同时最后几位为0000,所以 minrun 为61,⌈n/minrun⌉=16 满足要求
static Py_ssize_t
merge_compute_minrun(Py_ssize_t n)
{
Py_ssize_t r = 0; /* becomes 1 if any 1 bits are shifted off */
assert(n >= 0);
while (n >= 64) {
r |= n & 1;
n >>= 1;
}
return n + r;
}
nRemaining = hi - lo
minrun = merge_compute_minrun(nRemaining)
用到的排序方法
我们会发现当数组元素个数小于7时,插入排序更合适
插入排序
归并排序
效率为O(nlog n)。 1945年由约翰·冯·诺伊曼首次提出。该算法是采用分治法(Divide and Conquer)的一个非常典型的应用,且各层分治递归可以同时进行。
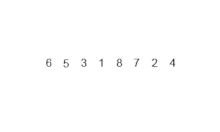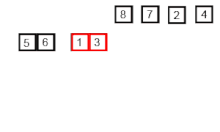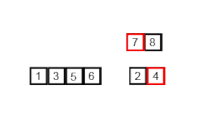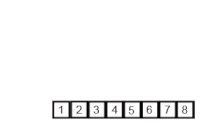
分治法
分割:递归地把当前序列平均分割成两半。 集成:在保持元素顺序的同时将上一步得到的子序列集成到一起(归并)
二分查找
一种在有序数组中查找某一特定元素的搜索算法
时间复杂度:O(log n)