Linked list
| EN | CN |
In computer science, a linked list is a linear collection of data elements, whose order is not given by their physical placement in memory. Instead, each element points to the next. It is a data structure consisting of a collection of nodes which together represent a sequence. In its most basic form, each node contains: data, and a reference (in other words, a link) to the next node in the sequence. This structure allows for efficient insertion or removal of elements from any position in the sequence during iteration. More complex variants add additional links, allowing more efficient insertion or removal of nodes at arbitrary positions. A drawback of linked lists is that access time is linear (and difficult to pipeline). Faster access, such as random access, is not feasible. Arrays have better cache locality compared to linked lists.
Linked lists are among the simplest and most common data structures. They can be used to implement several other common abstract data types, including lists, stacks, queues, associative arrays, and S-expressions, though it is not uncommon to implement those data structures directly without using a linked list as the basis.
The principal benefit of a linked list over a conventional array is that the list elements can be easily inserted or removed without reallocation or reorganization of the entire structure because the data items need not be stored contiguously in memory or on disk, while restructuring an array at run-time is a much more expensive operation. Linked lists allow insertion and removal of nodes at any point in the list, and allow doing so with a constant number of operations by keeping the link previous to the link being added or removed in memory during list traversal.
On the other hand, since simple linked lists by themselves do not allow random access to the data or any form of efficient indexing, many basic operations—such as obtaining the last node of the list, finding a node that contains a given datum, or locating the place where a new node should be inserted—may require iterating through most or all of the list elements. The advantages and disadvantages of using linked lists are given below. Linked list are dynamic, so the length of list can increase or decrease as necessary. Each node does not necessarily follow the previous one physically in the memory.
Create Linked list
class ListNode(object):
def __init__(self, x):
self.val = x
self.next = None
res = []
Add and Traversal
class Solution:
def __init__(self):
self.head = None
def add(self, head, x):
if not head:
head = ListNode(x)
else:
head.next = self.add(head.next, x)
return head
def add2(self, l):
if len(l) == 0:
return None
for i in range(len(l)):
self.head = self.add(self.head, l[i])
return self.head
def dfs(self, head):
if head:
res.append(head.val)
self.dfs(head.next)
return res
Delete
def delete(self, head, x):
if not head or not head.next:
return None
a = head
b = head.next
if x != head.val:
head.next = self.delete( head.next, x)
if b.val == x:
a.next = b.next
return head
Search
def search(self, x):
node = self.head
found = False
while not found and node:
if node.val == x:
print("We found this node in the linked list")
found = True
return node
else:
node = node.next
print("We can't found this node")
Insert
def insert(self, index, x):
'''
index->int: 索引要插入的地方
x->int: 要插入的值
'''
if not self.head:
return None
node = self.search(index)
if node:
tmp = ListNode(x)
node.next = tmp
tmp.next = node.next.next
return self.head
Update
def update(self, index, x):
'''
index->int: original node
x->int: new node
'''
if not self.head:
return None
node = self.search(index)
if node:
node.val = x
print("Update success!")
else:
return None
return node
Reverse Linked list
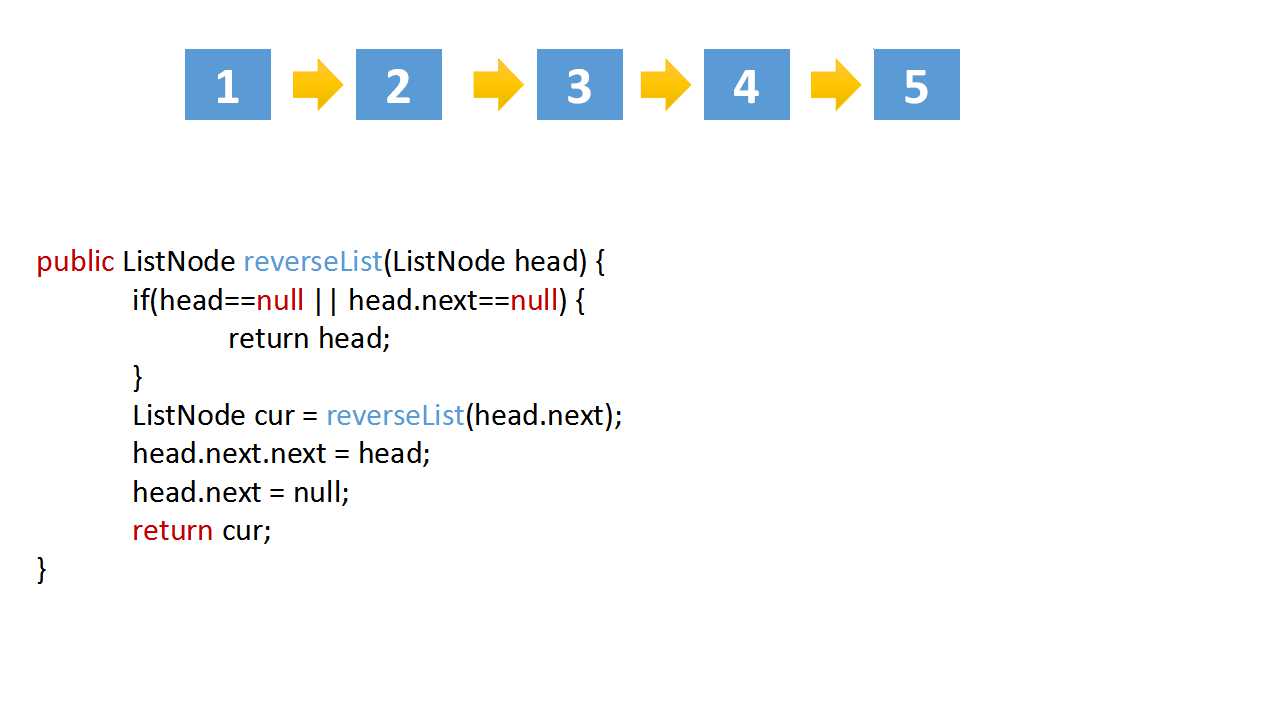


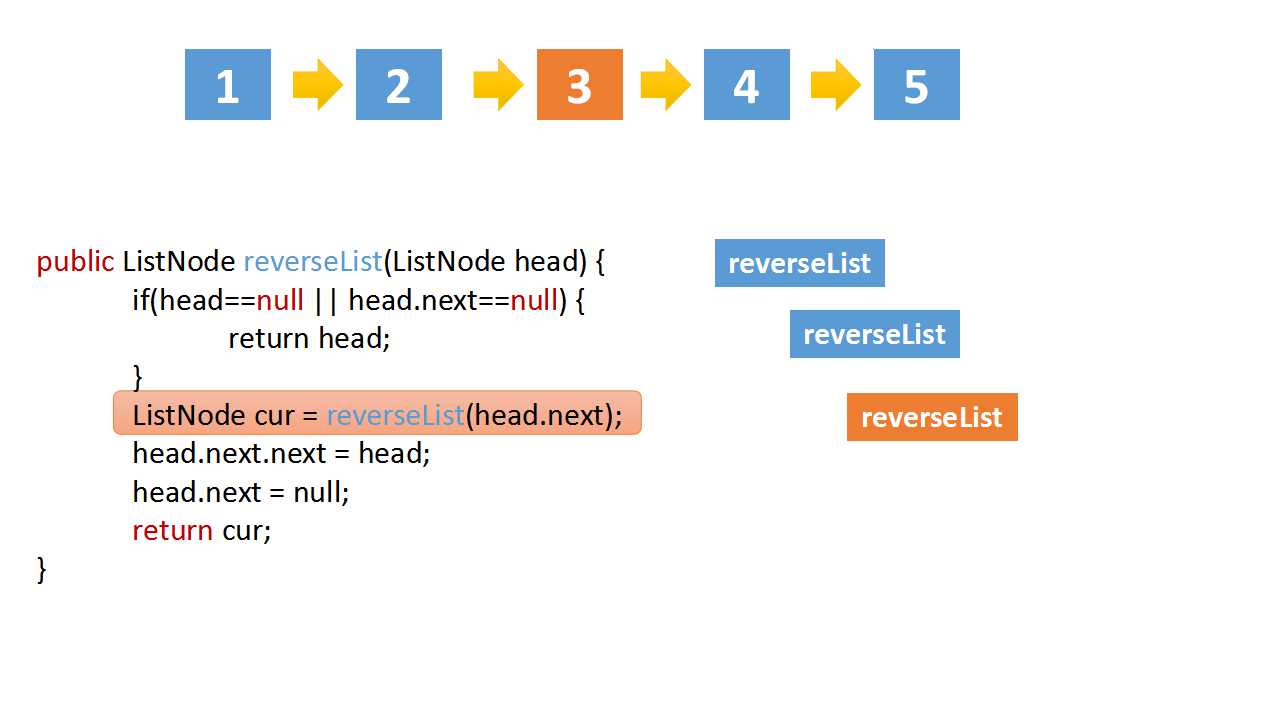
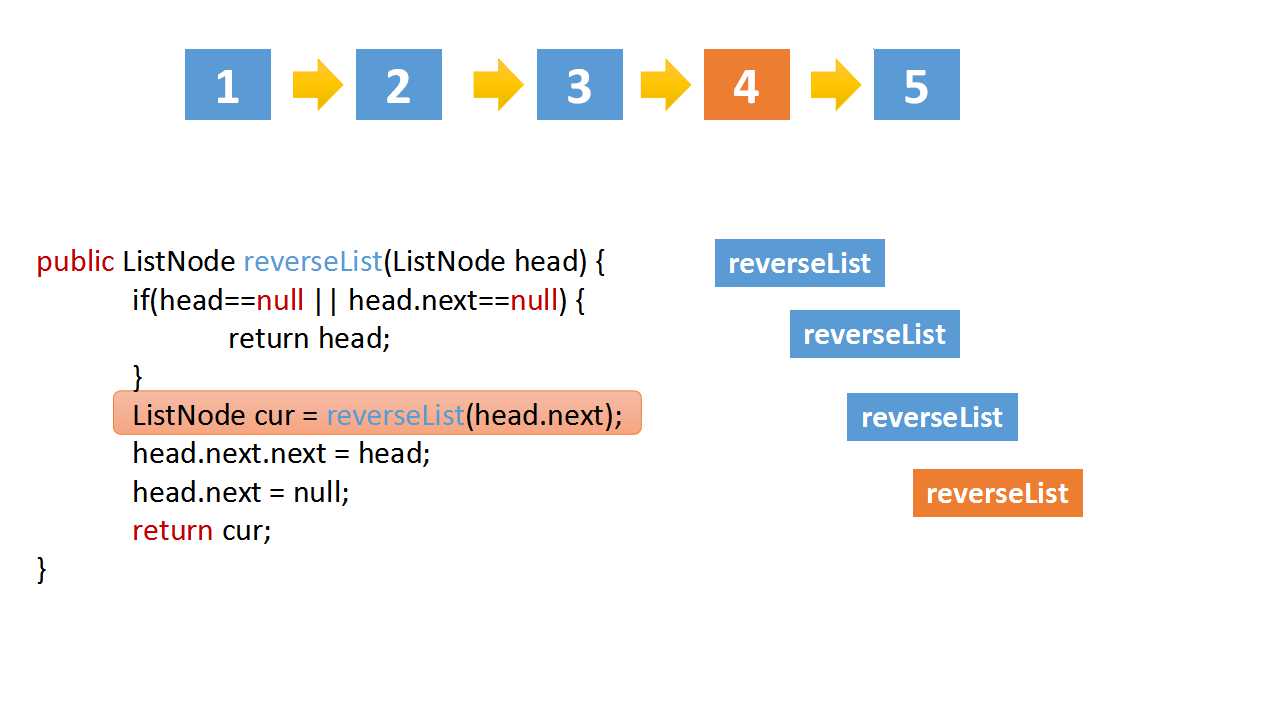
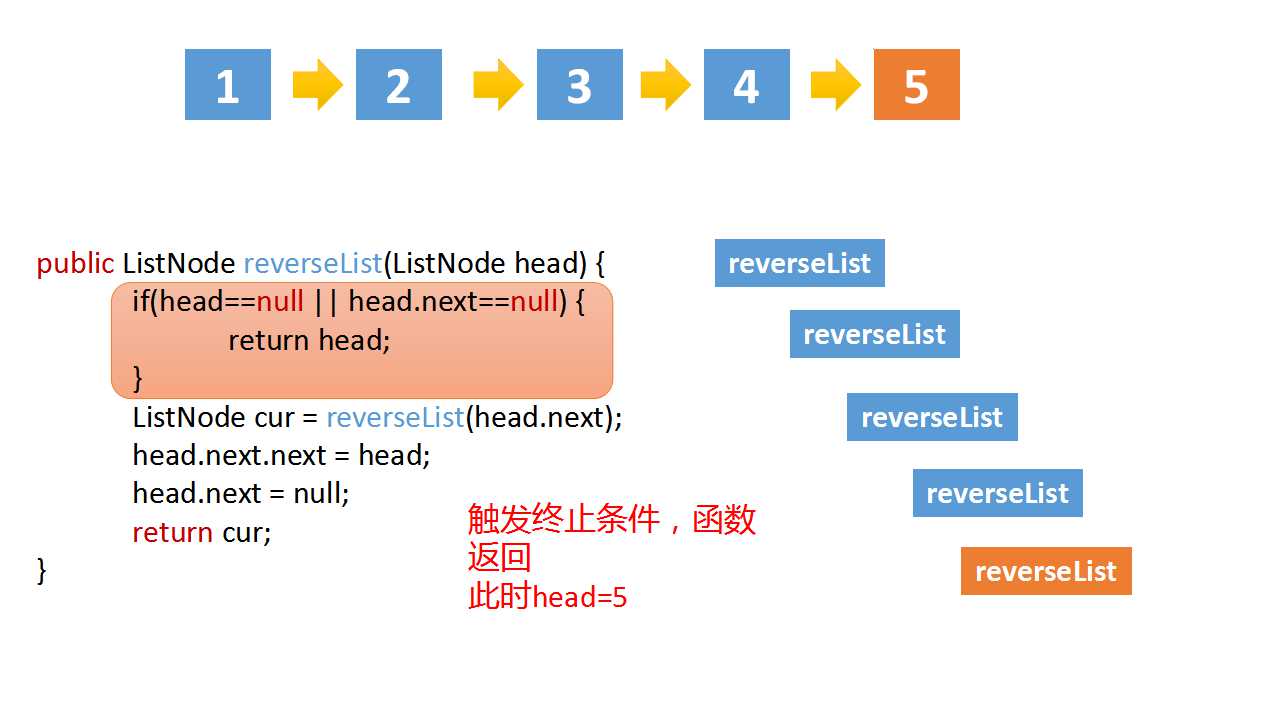
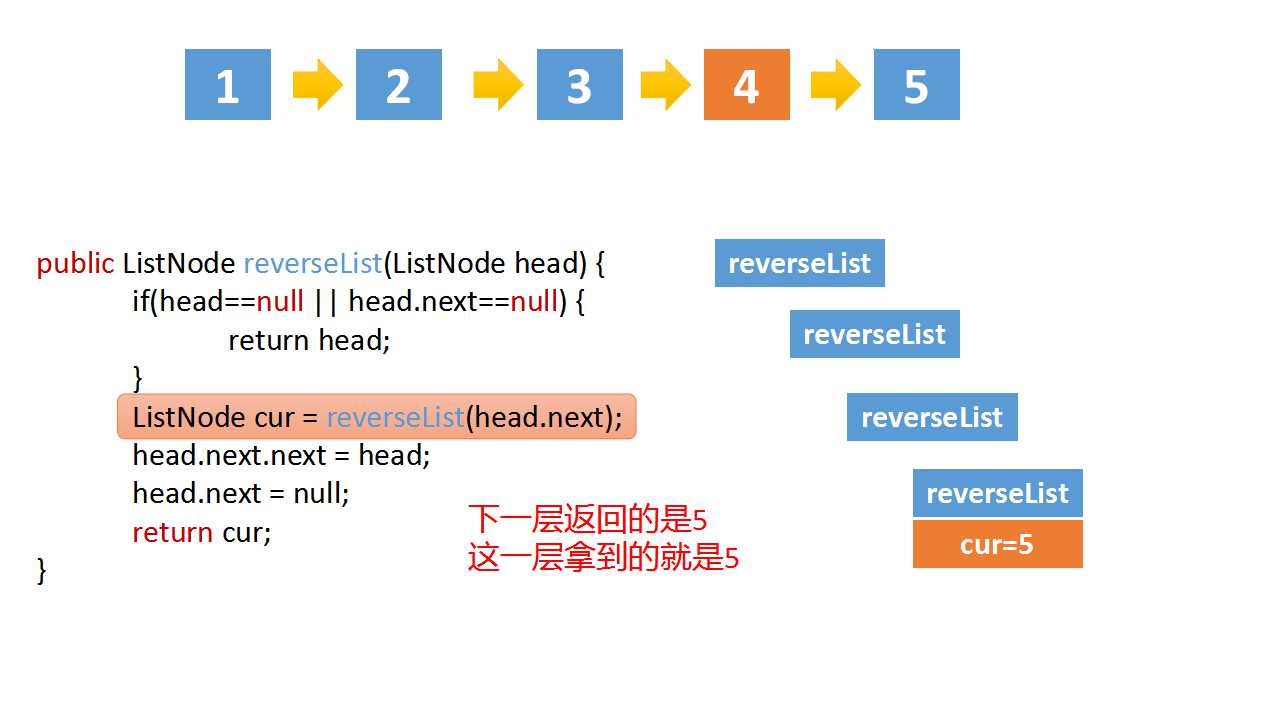
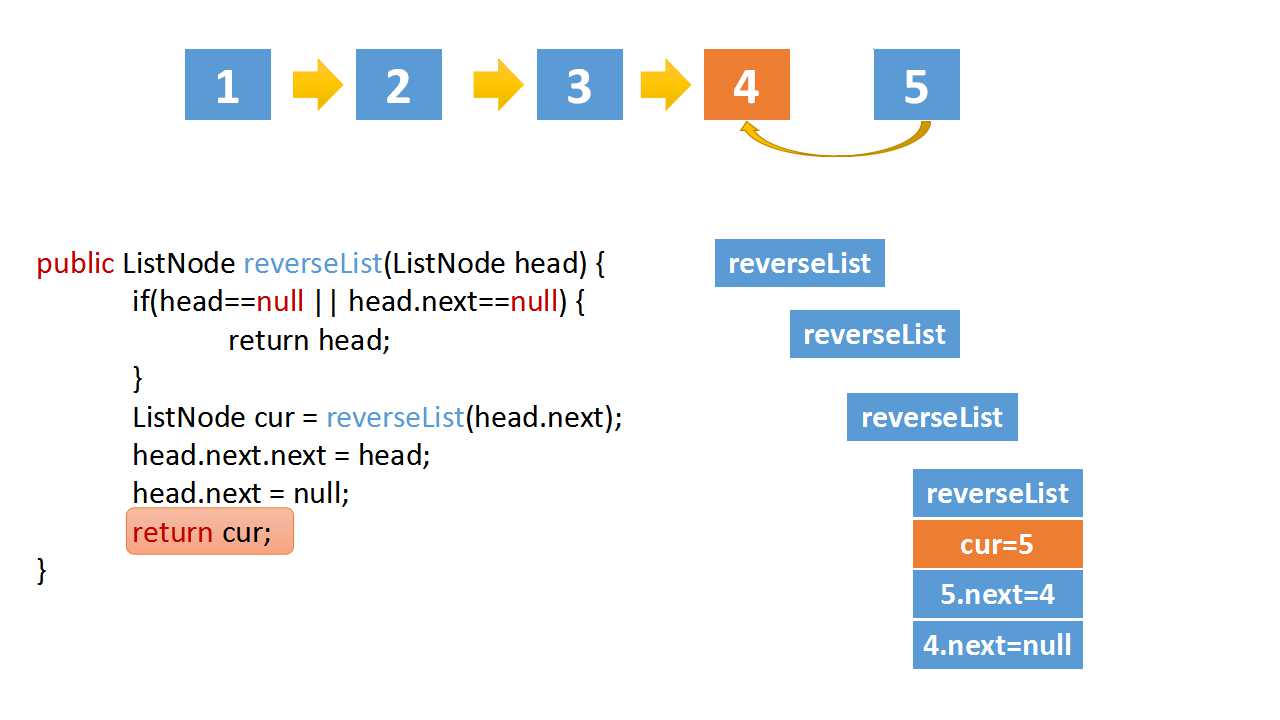
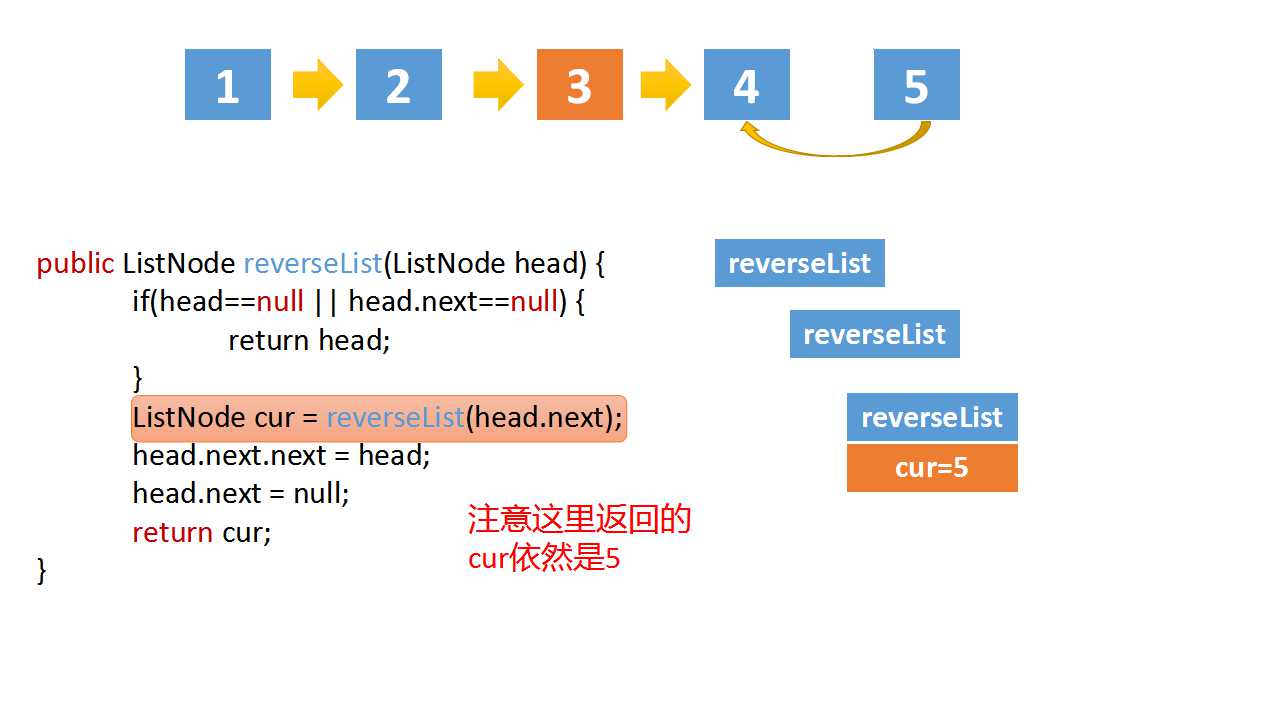
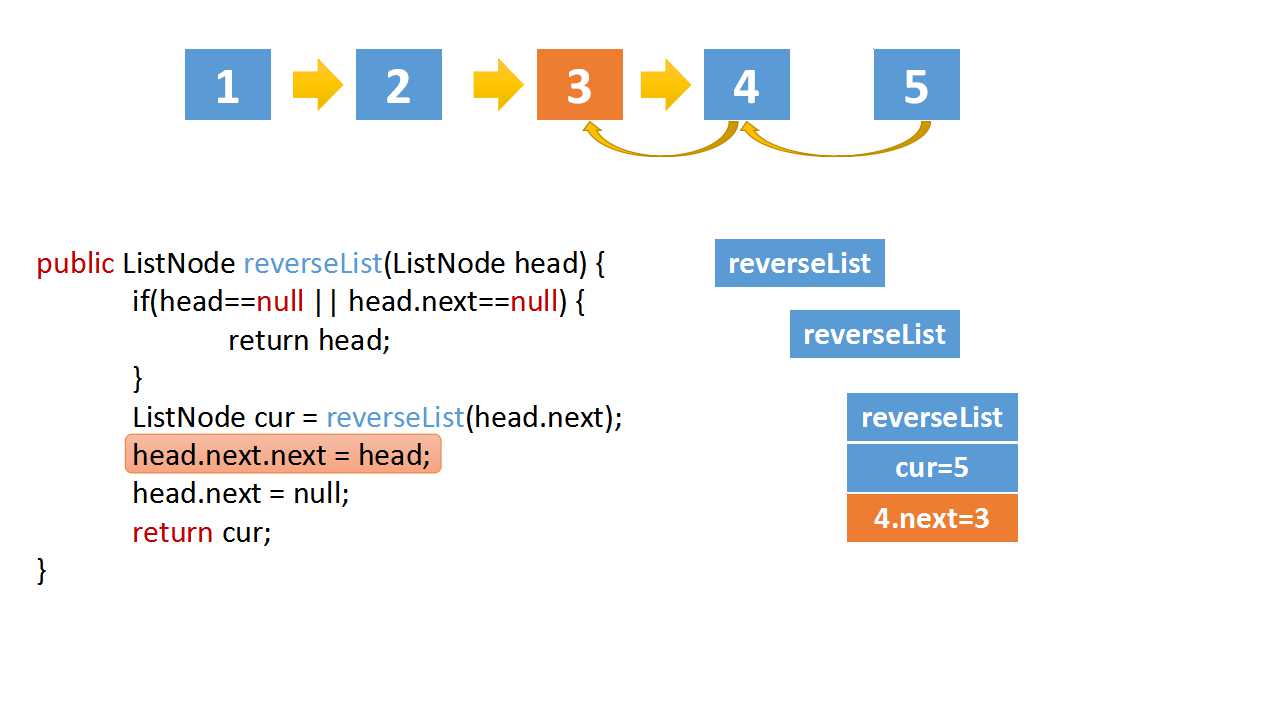
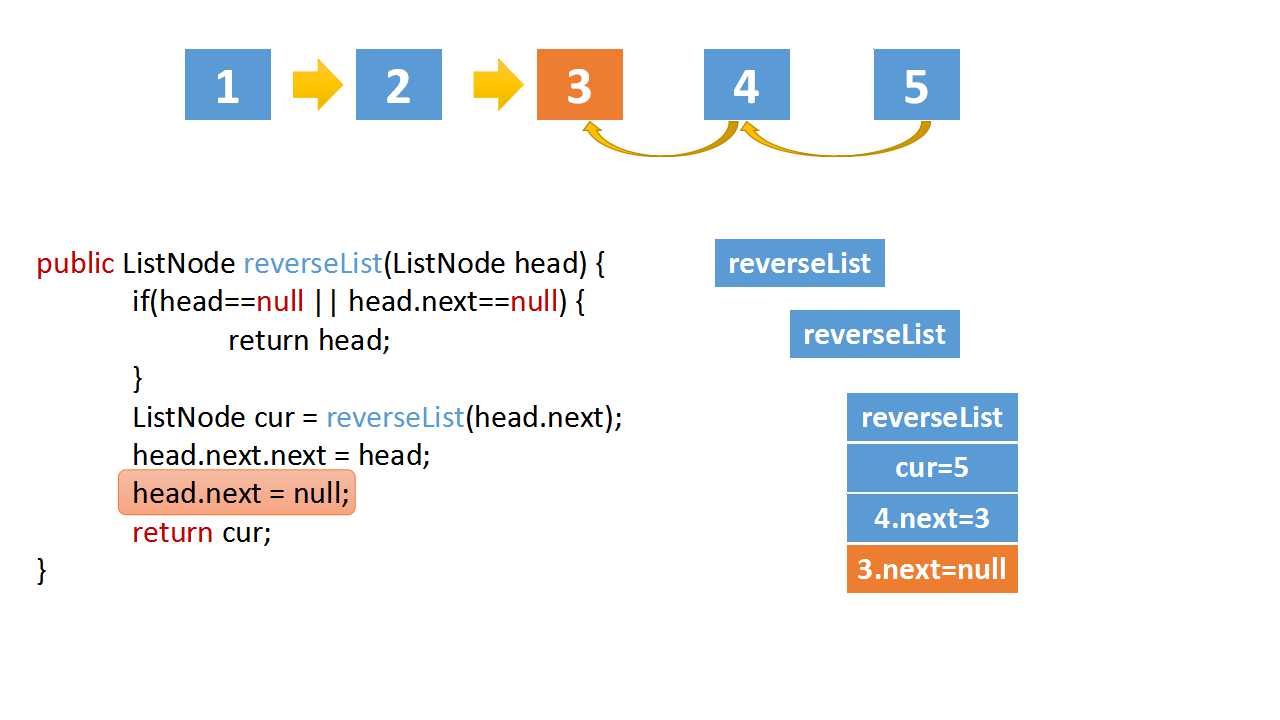
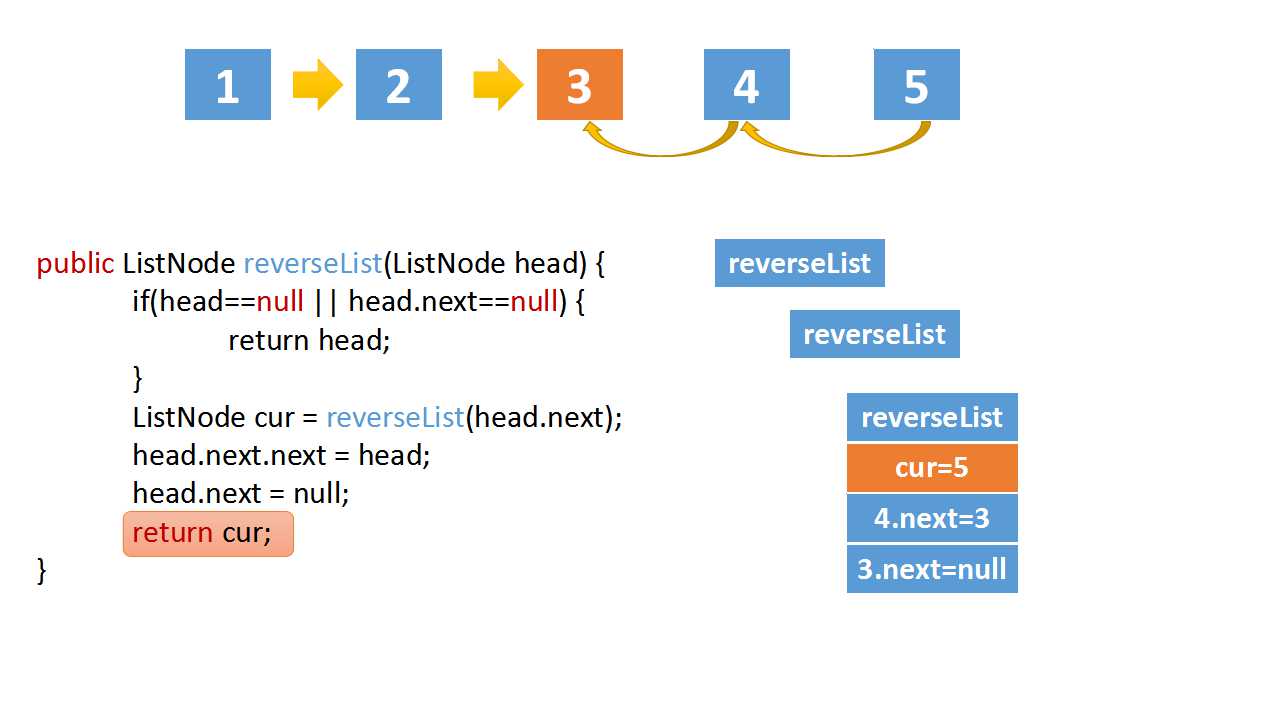
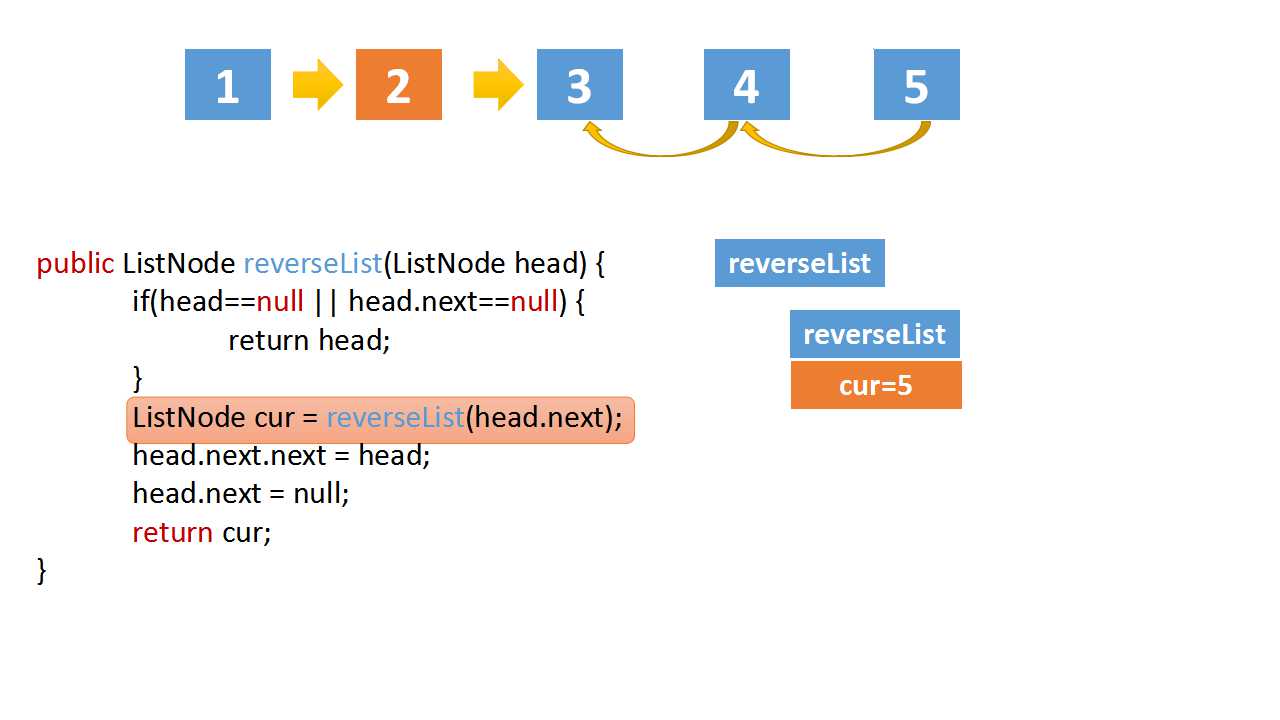
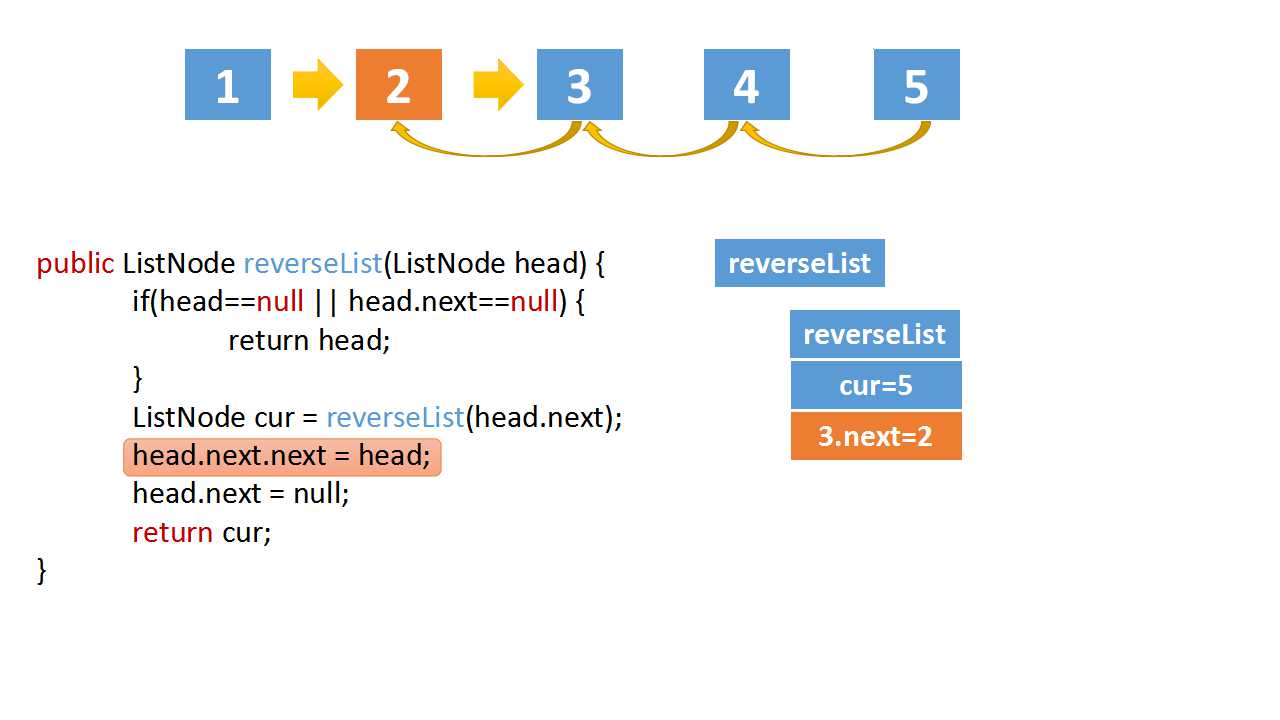
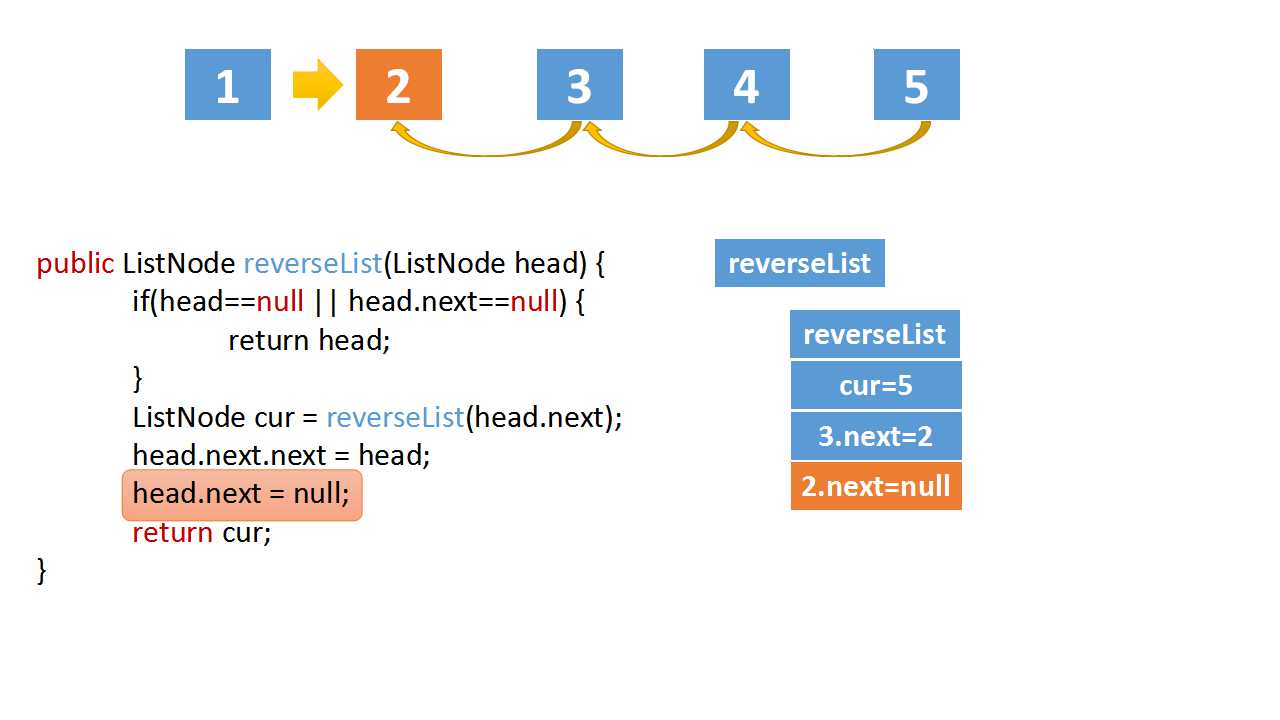
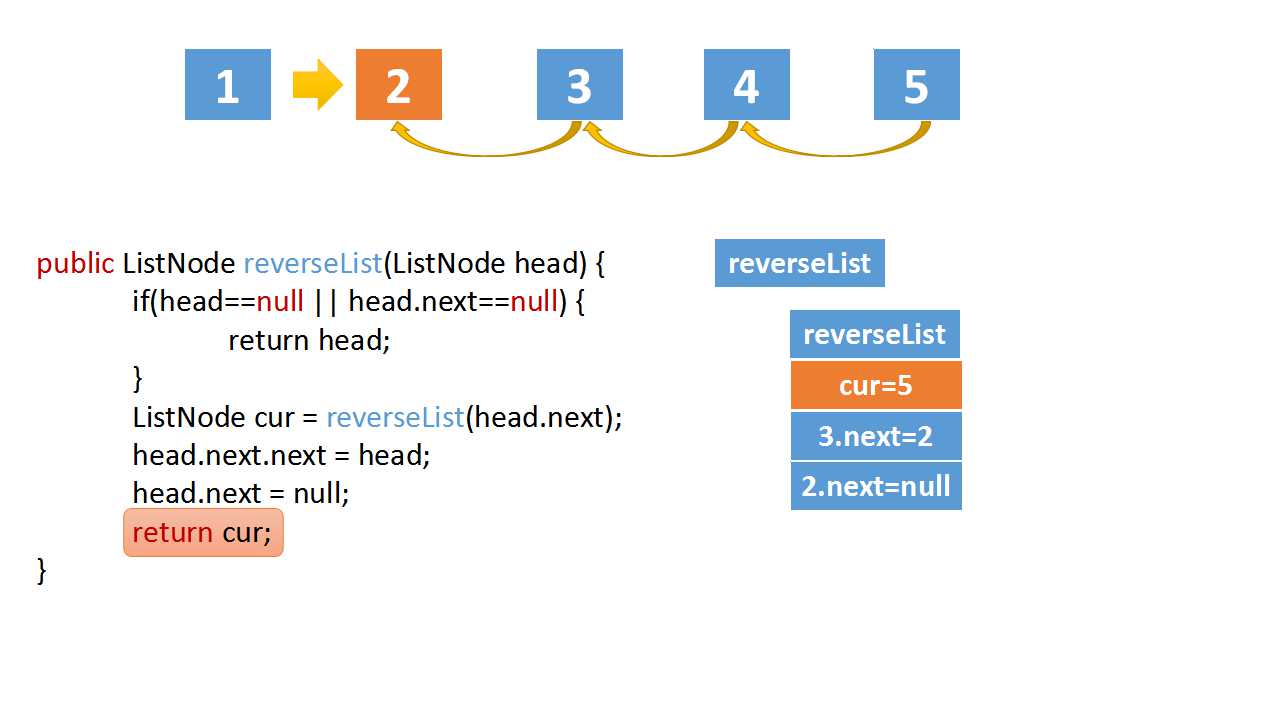
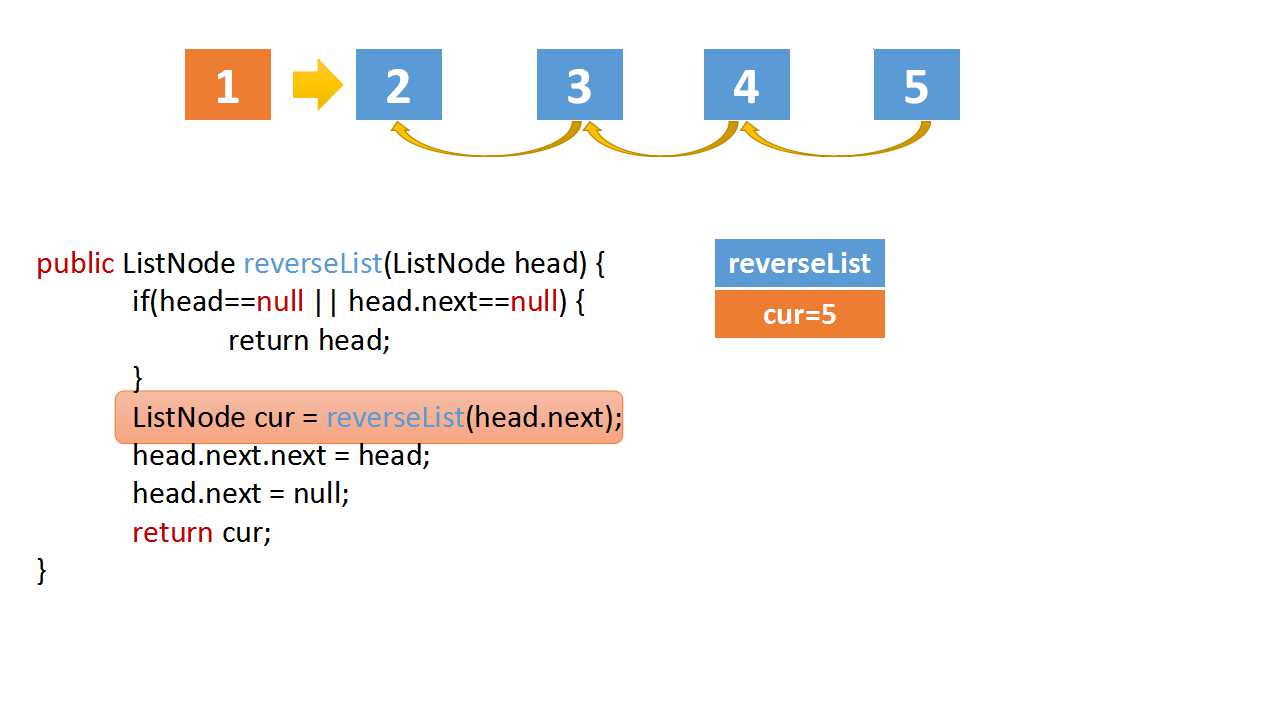

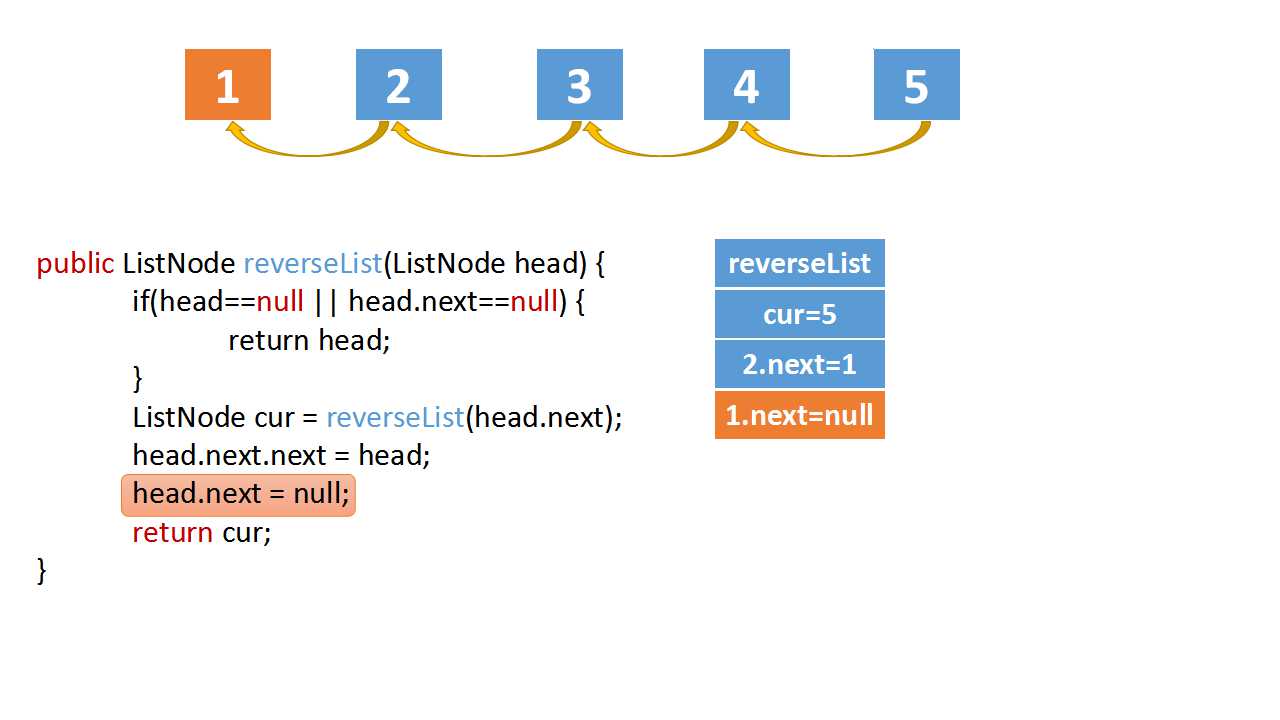
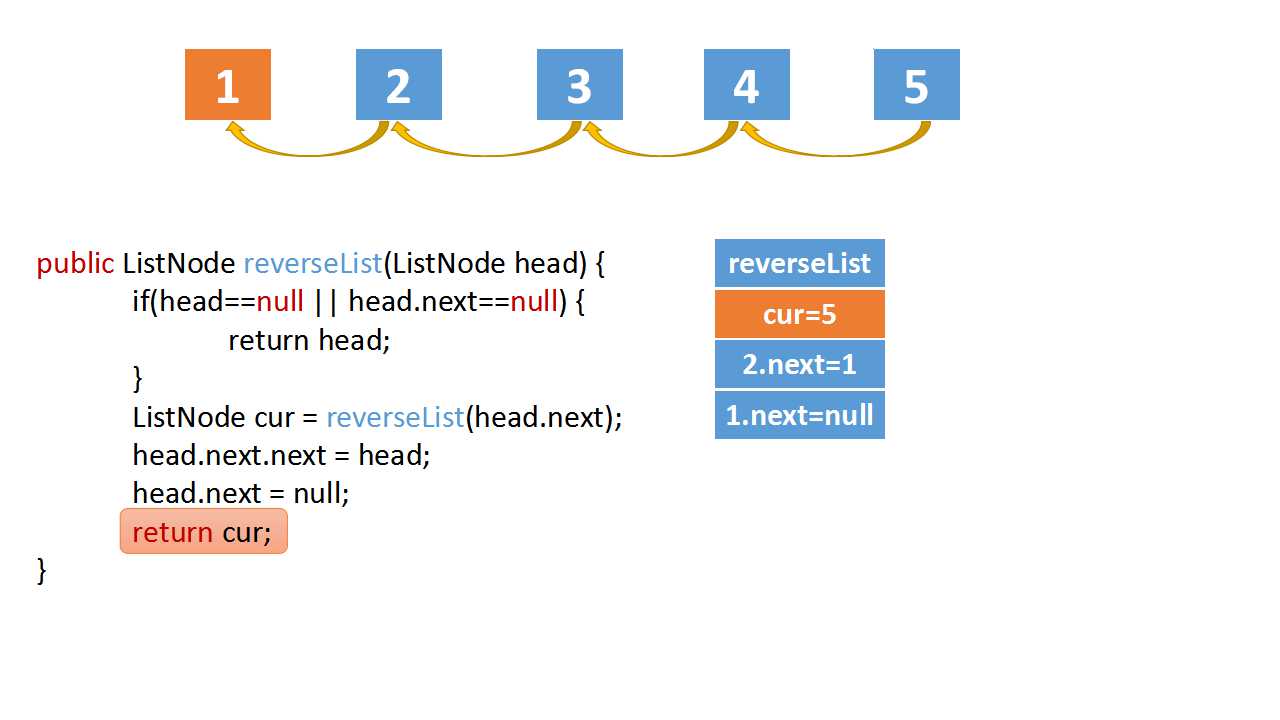

class Solution(object):
def reverseList(self, head):
"""
:type head: ListNode
:rtype: ListNode
"""
# The recursive termination condition is that the current is empty, or the next node is empty
if(head==None or head.next==None):
return head
# the cur is last node
cur = self.reverseList(head.next)
# if the linked list is 1->2->3->4->5,cur is 5
# head.val = 4,head.next.val = 5
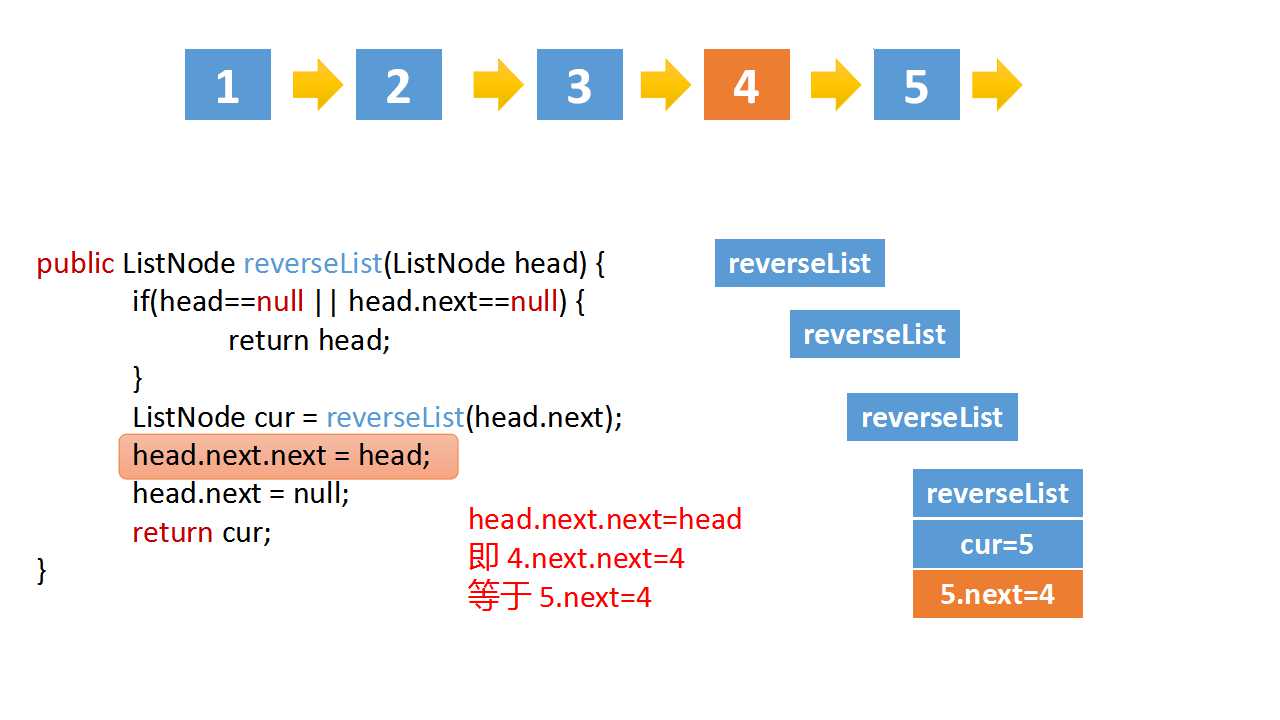
# head.next.next => 5->4
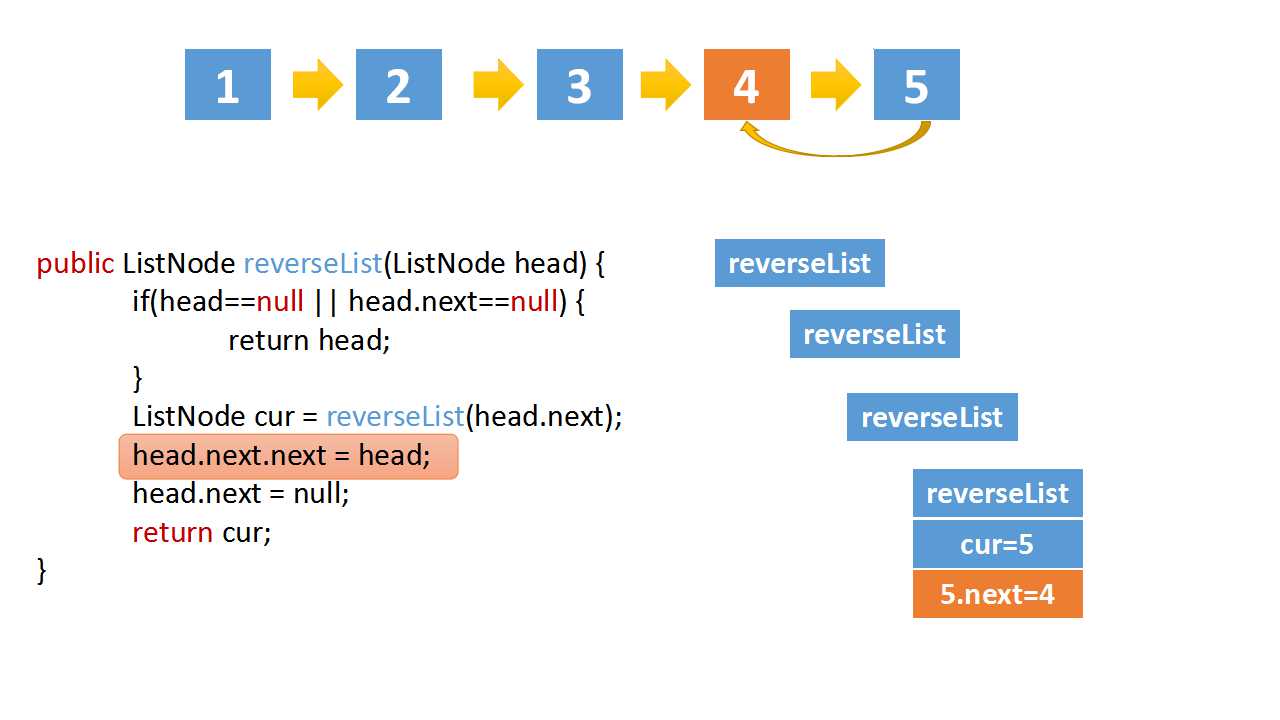
head.next.next = head
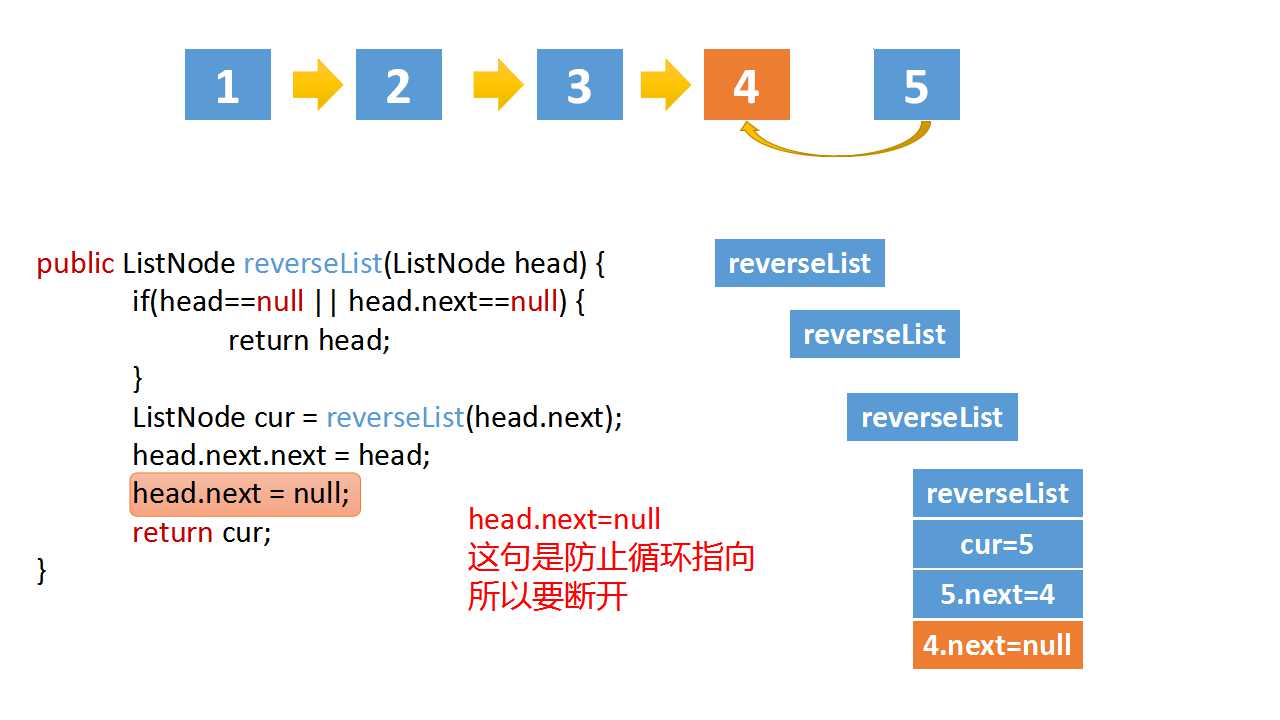
head.next = None
return cur
Source code
链表
链表(Linked list)是一种常见的基础数据结构,是一种线性表,但是并不会按线性的顺序存储数据,而是在每一个节点里存到下一个节点的指针(Pointer)。由于不必须按顺序存储,链表在插入的时候可以达到O(1)的复杂度,比另一种线性表顺序表快得多,但是查找一个节点或者访问特定编号的节点则需要O(n)的时间,而顺序表相应的时间复杂度分别是O(logn)和O(1)。
使用链表结构可以克服数组链表需要预先知道数据大小的缺点,链表结构可以充分利用计算机内存空间,实现灵活的内存动态管理。但是链表失去了数组随机读取的优点,同时链表由于增加了结点的指针域,空间开销比较大。
在计算机科学中,链表作为一种基础的数据结构可以用来生成其它类型的数据结构。链表通常由一连串节点组成,每个节点包含任意的实例数据(data fields)和一或两个用来指向上一个/或下一个节点的位置的链接(”links”)。链表最明显的好处就是,常规数组排列关联项目的方式可能不同于这些数据项目在记忆体或磁盘上顺序,数据的访问往往要在不同的排列顺序中转换。而链表是一种自我指示数据类型,因为它包含指向另一个相同类型的数据的指针(链接)。链表允许插入和移除表上任意位置上的节点,但是不允许随机存取。链表有很多种不同的类型:单向链表,双向链表以及循环链表。
链表的创建
1
2
3
4
5
class ListNode(object):
def __init__(self, x):
self.val = x
self.next = None
res = []
添加和遍历
class Solution:
def __init__(self):
self.head = None
def add(self, head, x):
if not head:
head = ListNode(x)
else:
head.next = self.add(head.next, x)
return head
def add2(self, l):
if len(l) == 0:
return None
for i in range(len(l)):
self.head = self.add(self.head, l[i])
return self.head
def dfs(self, head):
if head:
res.append(head.val)
self.dfs(head.next)
return res
删除
def delete(self, head, x):
if not head or not head.next:
return None
a = head
b = head.next
if x != head.val:
head.next = self.delete( head.next, x)
if b.val == x:
a.next = b.next
return head
查询
def search(self, x):
node = self.head
found = False
while not found and node:
if node.val == x:
print("We found this node in the linked list")
found = True
return node
else:
node = node.next
print("We can't found this node")
插入
def insert(self, index, x):
'''
index->int: 索引要插入的地方
x->int: 要插入的值
'''
if not self.head:
return None
node = self.search(index)
if node:
tmp = ListNode(x)
node.next = tmp
tmp.next = node.next.next
return self.head
更新
def update(self, index, x):
'''
index->int: original node
x->int: new node
'''
if not self.head:
return None
node = self.search(index)
if node:
node.val = x
print("Update success!")
else:
return None
return node
反转链表
class Solution(object):
def reverseList(self, head):
"""
:type head: ListNode
:rtype: ListNode
"""
# 递归终止条件是当前为空,或者下一个节点为空
if(head==None or head.next==None):
return head
# 这里的cur就是最后一个节点
cur = self.reverseList(head.next)
# 这里请配合动画演示理解
# 如果链表是 1->2->3->4->5,那么此时的cur就是5
# 而head是4,head的下一个是5,下下一个是空
# 所以head.next.next 就是5->4
head.next.next = head
# 防止链表循环,需要将head.next设置为空
head.next = None
# 每层递归函数都返回cur,也就是最后一个节点
return cur