Pooling
池化是卷积神经网络中的重要组成部分, 根据任务需求, 模型架构和计算资源所使用的池化也有所不同,其中最常见的是最大池化(Max Pooling)和平均池化(Average Pooling), 而空间金字塔池化统一输入图像的尺度,全局池化是为了减小参数
以下总结了不同池化的不同操作目的和常见的应用
| 池化类型 | 操作 | 优势 | 常见应用 |
|---|---|---|---|
| 最大池化 (Max Pooling) | 在池化窗口内选择最大值。 | 保留最显著特征,强调边缘和纹理信息。 | 大多数卷积神经网络(如VGG、ResNet)。 |
| 平均池化 (Average Pooling) | 在池化窗口内计算平均值。 | 更平滑的特征图,减少对噪声的敏感性。 | GoogleNet(Inception模块)等。 |
| 全局平均池化 (Global Average Pooling) | 对整个特征图的所有元素求平均。 | 显著减少参数数量,避免过拟合,保持信息平滑。 | ResNet、DenseNet的分类任务。 |
| 全局最大池化 (Global Max Pooling) | 对整个特征图的所有元素选择最大值。 | 强调最显著的特征,减少参数数量。 | 强调关键特征的任务,如目标检测和分类。 |
| 随机池化 (Stochastic Pooling) | 在池化窗口内随机选择一个元素。 | 引入随机性增加鲁棒性,避免过拟合。 | 一些实验性网络(如深度自编码器)。 |
| 卷积池化 (Convolutional Pooling) | 使用卷积层代替池化层来进行下采样。 | 通过学习卷积核提取更多有意义的特征,捕捉复杂模式。 | Capsule Networks等深度学习架构。 |
| 空间金字塔池化 (Spatial Pyramid Pooling, SPP) | 在多个尺度上进行池化操作,提取不同尺度的特征。 | 处理不同尺寸的输入图像,避免裁剪,捕捉多尺度空间信息。 | 目标检测任务(如SPP-net)。 |
| 带步长池化 (Strided Pooling) | 设置池化窗口的步长,控制特征图的下采样率。 | 控制下采样的程度,影响特征图的尺寸和信息密度。 | 图像处理中的下采样操作。 |
| 非局部池化 (Non-Local Pooling) | 考虑全局信息或远距离像素之间的关系进行池化。 | 捕捉图像中的长程依赖关系,提升全局信息的理解。 | 图像生成、视觉理解任务。 |
这个表格总结了常见池化方法的操作、优势以及适用场景,帮助快速理解每种池化方式的特点和使用场景。
这章主要精读的是Spatial Pyramid Pooling, 空间金字塔池
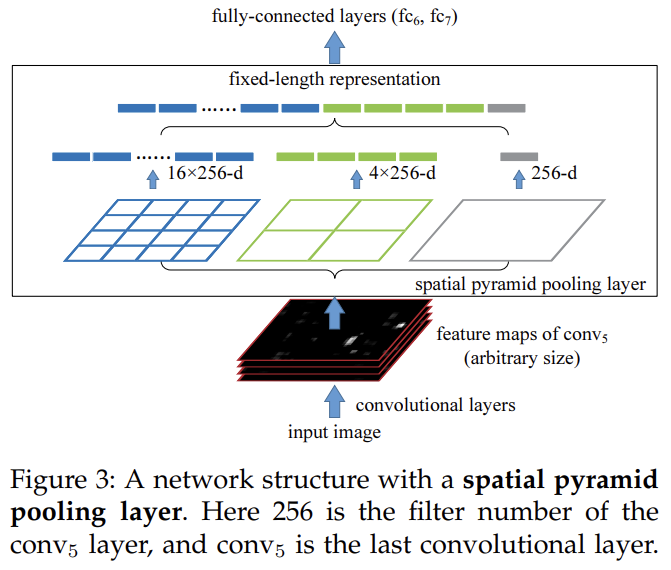
解决了什么问题
在多个尺度上进行池化操作,提取不同尺度的特征。避免裁剪导致空间信息丢失.
作者简介
1. Kaiming He
- 简介:Kaiming He 是计算机视觉和深度学习领域的著名学者,现为 Meta(前 Facebook)的研究员,并曾是微软研究院的资深研究员。He 教授在计算机视觉领域的贡献广泛,特别是在卷积神经网络(CNN)和深度学习架构方面。Kaiming He 是 ResNet(残差网络)的主要作者之一,该网络在深度学习领域引发了广泛关注。ResNet 引入的残差学习方法显著提高了网络的训练效率和精度。
- 学术背景:He 教授在中国的西安交通大学获得学士学位,之后获得了中国科学院自动化研究所的博士学位。他的研究涉及深度神经网络、计算机视觉、图像识别和机器学习等多个方向。
- 主要贡献:
- ResNet:提出了深度残差网络(ResNet),极大地推动了深度学习的发展。
- 深度学习算法的优化:在卷积神经网络、目标检测和图像分割等领域做出了重要贡献。
2. Xiangyu Zhang
- 简介:Xiangyu Zhang 是计算机视觉领域的研究人员,主要从事深度学习、计算机视觉以及视觉推理等方向的研究。Zhang 是多篇重要论文的作者,研究成果在学术界和工业界具有广泛影响。他曾在多个知名的学术会议和期刊上发表文章,并获得了多项荣誉和奖项。
- 学术背景:他在中国科学院自动化研究所获得博士学位,并继续从事计算机视觉和深度学习的研究。
- 主要贡献:
- 在目标检测、图像分类等计算机视觉任务中提出了多个创新算法,推动了深度学习在实际应用中的进展。
3. Shaoqing Ren
- 简介:Shaoqing Ren 是计算机视觉领域的学者,特别关注深度学习和计算机视觉任务中的优化算法。他是 Region-based CNN (R-CNN) 系列算法的重要贡献者之一,这一系列算法为目标检测和图像分割等任务提供了显著的性能提升。
- 学术背景:Ren 在中国科学院自动化研究所获得博士学位,之后在微软研究院工作。他的研究成果在深度学习和计算机视觉的多个领域具有重要影响。
- 主要贡献:
- R-CNN 系列:提出了 R-CNN 和 Fast R-CNN 等重要算法,这些算法对目标检测领域产生了深远影响。
- 在图像分类、目标检测、语义分割等多个计算机视觉领域做出了杰出的贡献。
4. Jian Sun
- 简介:Jian Sun 是计算机视觉领域的专家,特别擅长深度学习和图像处理方面的研究。他是计算机视觉中多个基础性算法的提出者之一,尤其在目标检测、图像分割和深度学习架构的优化方面取得了显著成果。
- 学术背景:Sun 博士在中国科学院获得博士学位,并曾在多个知名的国际学术机构工作。他的研究内容包括图像处理、目标识别、深度神经网络等。
- 主要贡献:
- 在图像分割和目标检测领域提出了多个有影响力的算法,尤其是在特征提取和网络优化方面有显著贡献。
- 参与了 R-CNN、Fast R-CNN 等重要计算机视觉算法的设计和实现。
优点
- 处理不同尺寸图像: 避免不同尺寸的图片的裁剪与缩放带来的信息丢失
- 多尺度特征提取: 不同的提取窗口,提取不同尺度下的特征,在不同的场景下更加robust
- 避免信息丢失
- 提高计算效率: 全图卷积一次,相比于RNN的先选取多个候选区然后对每个候选区进行卷积然后池化的效率,更快
- 增强鲁棒性
缺点
- 增加计算复杂度
- 池化窗口选择的影响: 依赖窗口尺度的选择来最大化特征信息的提取
- 模型复杂度提升:
- 可能导致过拟合
- 丢失精确空间位置信息
结构流程


- 输入图像:任意尺寸的图像。
- 卷积操作:得到固定通道数的特征图。
- 金字塔池化: - 按多尺度划分网格(如1x1,2x2,4x4) - 对每个网格单元执行池化,得到多层特征向量。
- 拼接输出:将各层特征向量拼接为固定长度(\(L = \sum_{n}^{k=1} k^2·C\), 其中𝑘是金字塔每一层网格的划分数, C是特征图的通道数)向量。
- 后续处理:将固定长度向量用于分类或其他任务。
数据集
1. ImageNet 2012
- 简介:ImageNet 是一个大型的图像数据集,包含超过 1000 个类别的图像,常用于图像分类和视觉识别任务。ImageNet 2012 是其中的一个子集,包含了 1000 个类,每类大约 1300 张图像。
- 用途:该数据集用于测试和评估 SP-net 在图像分类任务上的表现。
- 下载链接:ImageNet Download
2. Pascal VOC 2007
- 简介:Pascal VOC(Visual Object Classes)是一个包含多种物体类别的标准数据集,广泛用于目标检测和图像分割任务。Pascal VOC 2007 数据集包含了 20 个物体类别,并提供了目标检测任务所需的标注。
- 用途:该数据集被用于验证 SPP-net 在目标检测任务中的表现。
- 下载链接:Pascal VOC 2007 Download
3. Caltech 101
- 简介:Caltech 101 数据集是一个用于物体识别的标准数据集,包含了 101 个类别,每个类别的图像数量在 40 到 800 张之间。该数据集广泛用于图像分类和特征学习的研究。
- 用途:该数据集被用于测试 SPP-net 在图像分类任务上的效果。
- 下载链接:Caltech 101 Download
效果
图片分类
对于ImageNet 2012
可以看到SPP与所使用的卷积网络架构无关,且提高了4种不同卷积架构的准确性.
- Single-size是固定输入尺寸(224x224)
- Multi-size是指在每个epoch从[180, 224]中随机均匀地取样尺寸为(s x s)
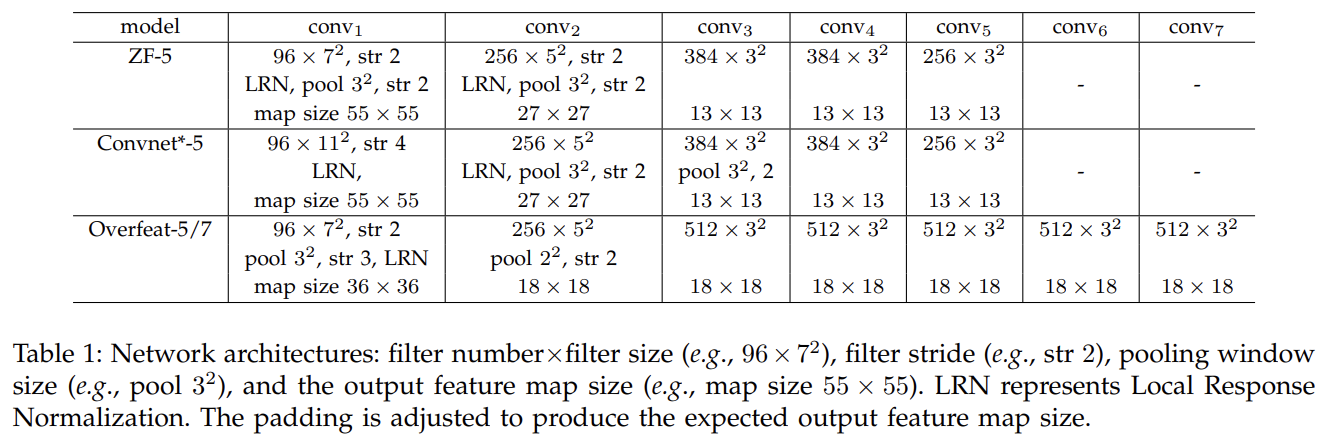
- ZF-5: 使用的是基于Zeiler和Fergus的”快速”较小模型的5层卷积层
- Convnet-5: 对于Krizhevsky等人的网络架构的修改,两个池化层放在Conv2和Conv3后面而不是放在Conv1和Conv2后面.它的特征图和ZF-5的大小相同
- Overfeat05/7: 基于Overfeat论文的修改.相对于ZF-5和Convnet*-5, 在最后一个池化层前使用的特征图尺寸更大18x18而不是13x13, Conv3以后的滤波器数量为512.而且还增加到了7层卷积,其中Conv3到Conv7是相同的架构.
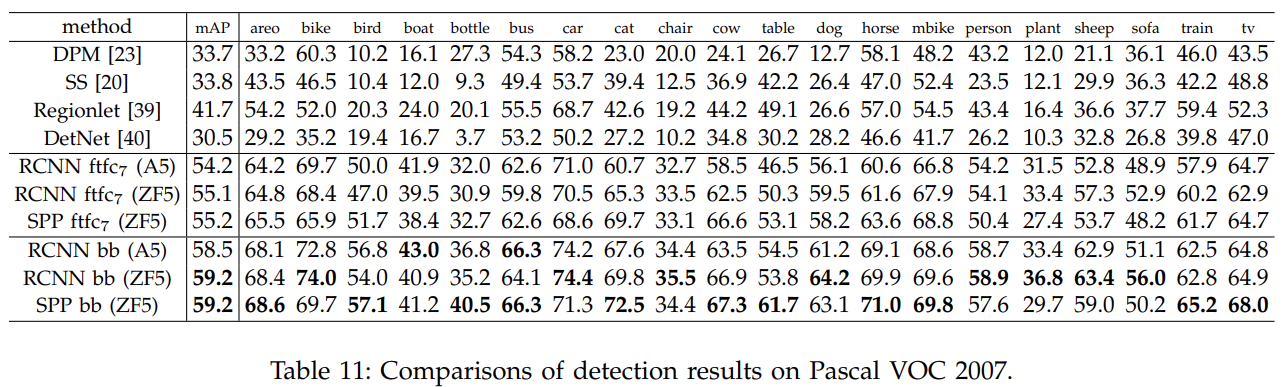
对于Pascal VOC 2007
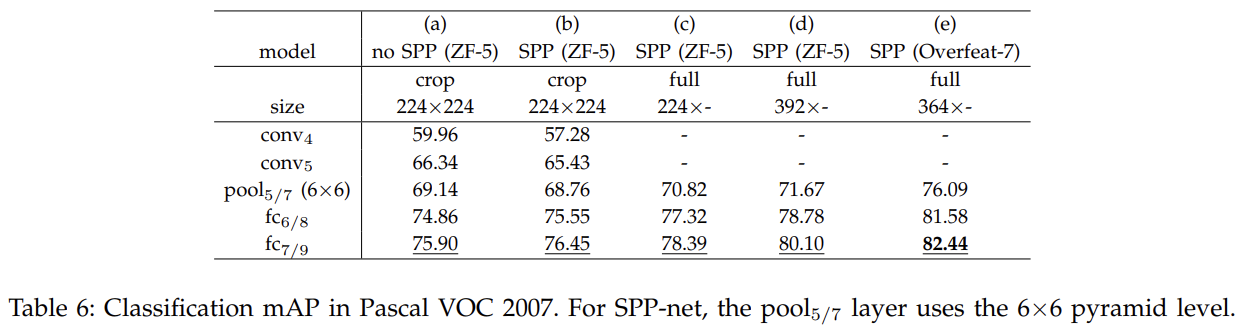
- 其中a和b比较, 在增加SPP下的ZF-5模型架构中, 正确率更大.
- c和b比较, 在全图下, 比裁剪的mAP更大,信息更多
- d和c比较, 在全图下, 输入的尺寸最小边更大, 得到的mAP更佳
对于Caltech 101
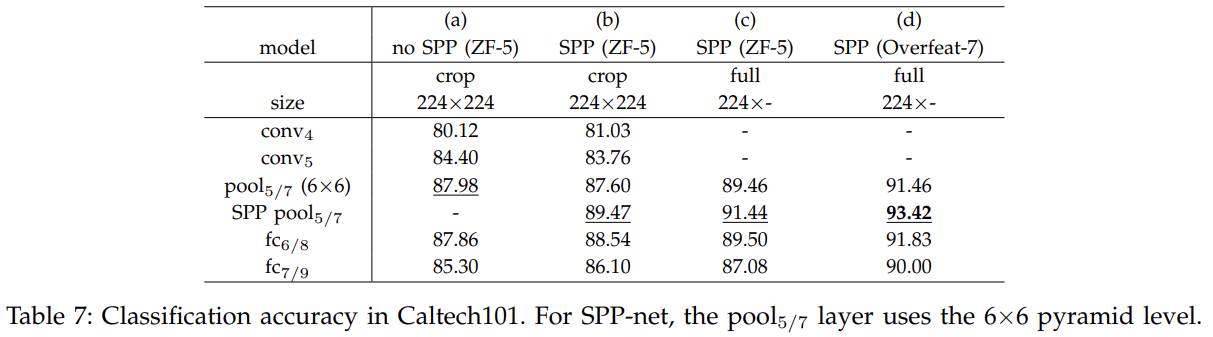
- a和b比较, 使用SPP,mAP更佳
- b和c比较, 全图比裁剪,mAP更佳
- c和d比较, Overfeat-7模型架构比ZF-5,mAP更佳
目标检测
对比R-CNN
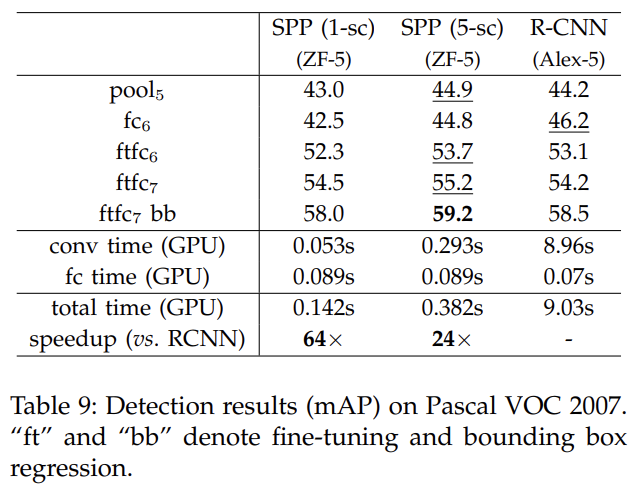
- ftfc7: fine-tuned fully connect layer 7th
- bb: bounding box 边界框回归, 预测物体所在位置
- 1-sc和5-sc: sc = scale, 不同的输入尺寸或者池化窗口
Code精读
金字塔池化层的python实现
import math
def spatial_pyramid_pool(self,previous_conv, num_sample, previous_conv_size, out_pool_size):
'''
previous_conv: a tensor vector of previous convolution layer上一层卷积输出的张量
num_sample: an int number of image in the batch 批量中图像的数量
previous_conv_size: an int vector [height, width] of the matrix features size of previous convolution layer上一卷积层的输出的特征图矩阵向量的大小,通常是[height, width]
out_pool_size: a int vector of expected output size of max pooling layer一个int型数组, 表示不同尺度中的期望最大池化层输出的大小
returns: a tensor vector with shape [1 x n] is the concentration of multi-level pooling返回一个[1xn]的张量
'''
# print(previous_conv.size())
for i in range(len(out_pool_size)):
# print(previous_conv_size)
h_wid = int(math.ceil(previous_conv_size[0] / out_pool_size[i]))
w_wid = int(math.ceil(previous_conv_size[1] / out_pool_size[i]))
h_pad = (h_wid*out_pool_size[i] - previous_conv_size[0] + 1)/2
w_pad = (w_wid*out_pool_size[i] - previous_conv_size[1] + 1)/2
maxpool = nn.MaxPool2d((h_wid, w_wid), stride=(h_wid, w_wid), padding=(h_pad, w_pad))
x = maxpool(previous_conv)
if(i == 0):
spp = x.view(num_sample,-1)
# print("spp size:",spp.size())
else:
# print("size:",spp.size())
spp = torch.cat((spp,x.view(num_sample,-1)), 1)
return spp
| 步骤 | 公式 | 解释 | |
|---|---|---|---|
| 池化窗口大小计算 | \(h_{\text{wid}} = \lceil \frac{H_{\text{prev}}}{\text{out\_pool\_size}[i]} \rceil\) \(\quad w_{\text{wid}} = \lceil \frac{W_{\text{prev}}}{\text{out\_pool\_size}[i]} \rceil\) | 计算当前池化尺度的池化窗口大小。 | |
| 池化填充计算 | \(h_{\text{pad}} = \frac{(h_{\text{wid}} \times \text{out\_pool\_size}[i] - H_{\text{prev}} + 1)}{2}\) \(\quad w_{\text{pad}} = \frac{(w_{\text{wid}} \times \text{out\_pool\_size}[i] - W_{\text{prev}} + 1)}{2}\) | 计算池化时所需的填充量,确保输出尺寸正确。 | |
| 池化操作 | \(X_{\text{pool}}^i = \text{MaxPool}(X_{\text{prev}}, h_{\text{wid}}, w_{\text{wid}}, h_{\text{pad}}, w_{\text{pad}})\) | 对输入特征图 \(X_{\text{prev}}\) 进行池化操作,得到池化结果 \(X_{\text{pool}}^i\)。 | |
| 展平操作 | \(X_{\text{flat}}^i = \text{Flatten}(X_{\text{pool}}^i)\) | 将池化后的结果 \(X_{\text{pool}}^i\) 展平为一维向量 \(X_{\text{flat}}^i\)。 | |
| 拼接操作 | \(\text{SPP}(X) = \text{Concat}(X_{\text{flat}}^1, X_{\text{flat}}^2, \dots, X_{\text{flat}}^m)\) | 将所有尺度的展平池化结果拼接成一个大向量,得到最终的空间金字塔池化结果。 |
金字塔池化层网络SPPnet的python实现
import torch
import torch.nn as nn
from torch.nn import init
import functools
from torch.autograd import Variable
import numpy as np
import torch.nn.functional as F
from spp_layer import spatial_pyramid_pool
class SPP_NET(nn.Module):
'''
A CNN model which adds spp layer so that we can input multi-size tensor
'''
def __init__(self, opt, input_nc, ndf=64, gpu_ids=[]):
super(SPP_NET, self).__init__()
self.gpu_ids = gpu_ids
self.output_num = [4,2,1]
self.conv1 = nn.Conv2d(input_nc, ndf, 4, 2, 1, bias=False)
self.conv2 = nn.Conv2d(ndf, ndf * 2, 4, 1, 1, bias=False)
self.BN1 = nn.BatchNorm2d(ndf * 2)
self.conv3 = nn.Conv2d(ndf * 2, ndf * 4, 4, 1, 1, bias=False)
self.BN2 = nn.BatchNorm2d(ndf * 4)
self.conv4 = nn.Conv2d(ndf * 4, ndf * 8, 4, 1, 1, bias=False)
self.BN3 = nn.BatchNorm2d(ndf * 8)
self.conv5 = nn.Conv2d(ndf * 8, 64, 4, 1, 0, bias=False)
self.fc1 = nn.Linear(10752,4096)
self.fc2 = nn.Linear(4096,1000)
def forward(self,x):
x = self.conv1(x)
x = self.LReLU1(x)
x = self.conv2(x)
x = F.leaky_relu(self.BN1(x))
x = self.conv3(x)
x = F.leaky_relu(self.BN2(x))
x = self.conv4(x)
# x = F.leaky_relu(self.BN3(x))
# x = self.conv5(x)
spp = spatial_pyramid_pool(x,1,[int(x.size(2)),int(x.size(3))],self.output_num)
# print(spp.size())
fc1 = self.fc1(spp)
fc2 = self.fc2(fc1)
s = nn.Sigmoid()
output = s(fc2)
return output
金字塔池化层SPP在ultralytics中的实现
class SPP(nn.Module):
"""Spatial Pyramid Pooling (SPP) layer https://arxiv.org/abs/1406.4729."""
def __init__(self, c1, c2, k=(5, 9, 13)):
"""Initialize the SPP layer with input/output channels and pooling kernel sizes."""
super().__init__()
c_ = c1 // 2 # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_ * (len(k) + 1), c2, 1, 1)
self.m = nn.ModuleList([nn.MaxPool2d(kernel_size=x, stride=1, padding=x // 2) for x in k])
def forward(self, x):
"""Forward pass of the SPP layer, performing spatial pyramid pooling."""
x = self.cv1(x)
return self.cv2(torch.cat([x] + [m(x) for m in self.m], 1))
| 步骤 | 代码 | 作用 | 设计目的 |
|—————————-|——————————————————-|———————————————————————————————————————————————————————————–|————————————————————————————————————————————————————————————|
| 1. 初始化参数 | c1, c2, k=(5, 9, 13) | 定义输入通道数 c1、输出通道数 c2,以及池化核大小列表 k,默认为 [5, 9, 13],表示5x5, 9x9, 13x13。 | 灵活地设置输入输出特征图的通道数以及池化操作的尺度,适应不同模型和任务的需求。 |
| 2. 计算隐藏通道数 | c_ = c1 // 2 | 将输入通道数 c1缩小一半,得到中间特征图的隐藏通道数 c_。 | 降低特征图的通道数,减少计算量,为后续拼接操作留出通道空间。 |
| 3. 定义卷积层 1 | self.cv1 = Conv(c1, c_, 1, 1) | 定义一个 1x1 卷积层,将输入特征图的通道数从 c1降到 c_,不改变特征图的空间尺寸。 | 利用 1x1 卷积减少通道数,提取重要特征,同时降低计算复杂度。 |
| 4. 定义最大池化模块 | self.m = nn.ModuleList([...]) | 创建一个 ModuleList,包含多个 nn.MaxPool2d 池化层,每个池化层的核大小分别为 k中的值,步幅为 1,填充为 kernel_size // 2。 | 不同核大小的池化操作能够捕获不同尺度的上下文信息,从而增强模型对多尺度目标的感知能力。 |
| 5. 定义卷积层 2 | self.cv2 = Conv(c_ * (len(k) + 1), c2, 1, 1) | 定义另一个 1x1 卷积层,将拼接后的特征图通道数从 c_ * (len(k) + 1)(包含原始特征图和池化后的特征图)压缩到 c2。 | 将多尺度特征图整合为指定的通道数,以适配后续网络结构。 |
| 6. 前向传播步骤 1 | x = self.cv1(x) | 输入特征图 x 经过第一个 1x1 卷积层,得到通道数缩减的中间特征图 x。 | 降低计算复杂度,同时提取重要的特征。 |
| 7. 前向传播步骤 2 | [m(x) for m in self.m] | 将中间特征图 x 依次传入 self.m 中的每个池化层,生成不同池化核大小下的特征图列表。 | 利用不同尺度的池化操作捕获多尺度上下文信息,增强特征表达能力。 |
| 8. 特征图拼接 | torch.cat([x] + [...], 1) | 将原始特征图 x 与池化后的特征图列表沿通道维度拼接,形成融合多尺度信息的特征图。 | 汇聚不同尺度的信息,为后续特征提取提供丰富的上下文线索。 |
| 9. 前向传播步骤 3 | return self.cv2(...) | 将拼接后的特征图通过第二个 1x1 卷积层,生成最终输出特征图,通道数为 c2。 | 进一步整合多尺度特征,压缩到指定通道数,便于后续模块使用。 |
设计差异
两者的核心思想都是进行 空间金字塔池化(Spatial Pyramid Pooling),即通过不同大小的池化窗口将特征图在不同尺度下进行池化,然后将池化后的特征拼接(concatenate)到一起,形成固定长度的特征表示。这使得网络能够处理不同大小的输入图像。
| 特性 | Ultralytics SPP | 自定义 spatial_pyramid_pool |
|---|---|---|
| 池化核大小 | 固定,使用 k=(5, 9, 13) 三个固定的池化大小 |
动态计算,基于 previous_conv_size 和 out_pool_size 计算每个池化核的大小 |
| 池化层的数量 | 固定数量,等于池化核的长度 k |
动态变化,取决于 out_pool_size 中的元素数量 |
| 卷积层的作用 | 卷积用于减小通道数(Conv(c1, c_, 1, 1)) |
没有卷积层进行通道压缩,主要通过池化操作 |
| 池化层步长 | 固定为 1,保持特征图大小 | 动态计算,基于池化窗口大小和填充 |
| 填充方式 | 使用 kernel_size // 2 进行中心对齐填充 |
动态计算填充大小,使得池化窗口能够精确对齐 |
| 特征融合 | 使用 torch.cat 拼接多个尺度的池化特征图 |
使用 torch.cat 拼接池化后的特征图,特征展平后拼接 |
参考
yueruchen/sppnet-pytorch ultralytics SPP
题外话
之所以取名为金字塔, 是因为它的结构和金字塔的实际形态类似:底部宽大,代表整体;顶部逐渐缩小,代表精细。